The Economics of Parallel Coding Agents
I watched a terminal tell me it had written a complete reservations module — entity, migration, DTOs, mapper, service, controller, ten stories, sixty-nine green Jest suites — in seven minutes and forty-five seconds.
Then I checked the bill. Four cents.
Not a toy. Not a stubbed-out happy path. A real vertical feature on a real NestJS backend, following the repo's own conventions, with the no-overlap and capacity rules enforced and the full existing suite still passing. DeepSeek charged me less than a US nickel and went back to idling.
I had sat down to write an architecture post — baro versus Claude Code, parallel agents versus one smart session. I got up writing an economics post. The fastest run of the day was also, by two orders of magnitude, the cheapest. And that stopped being a benchmark result and became a question: if bounded code costs four cents, what exactly am I paying frontier prices for?
The timing was not an accident. On May 28, 2026, Anthropic announced dynamic workflows in Claude Code: orchestration that fans a task out across many parallel subagents inside one session, exposed through an effort setting called ultracode that raises effort to xhigh and lets Claude decide when a workflow is worth it. Suddenly every timeline was screenshots of Claude splitting a task, running it in parallel, and coming back with a PR. It is a good direction. It is also the one we had been testing for a while with Mozaik and baro.
baro's bet has always been a little different from "make one agent smarter": turn a coding task into a DAG — plan once, split the work into bounded stories, run them in parallel, then reconcile. Mozaik is the event bus and participant model underneath; baro is the coding product on top. So when Claude Code moved into the same territory, I wanted a real comparison. Not a toy todo app. Not a screenshot race. The same repo, the same starting commit, the same acceptance bar, real pull requests at the end.
The task
The repo was the same private NestJS + TypeORM service I used in the 808-test run: shops, tables, menus, promotions, table sessions, role-based access, the kind of backend where conventions matter more than cleverness. The baseline was clean: 64 Jest suites, 808 tests, all green.
The task was a vertical feature: add a complete reservations module. Entity, migration, DTOs, mapper, service, controller, module wiring, and unit specs. The important rules were not cosmetic: no overlapping active reservations for the same table, party size capped by table capacity, time windows validated, status transitions enforced, soft delete, and the same NestJS guard/role conventions as the existing tables module.
I used the same starting commit and the same acceptance bar for every run: build must pass, the full Jest suite must pass, and the implementation has to follow the existing codebase shape rather than inventing a parallel universe.
Is parallel enough?
The first uncomfortable result was that Claude Code was better than I wanted it to be.
The pure-Claude baseline finished in 34 minutes. One Opus session, one workflow, one PR, full suite green. That matters. A single warm Claude Code session has advantages that are easy to underestimate when you are thinking in distributed-system diagrams: it keeps context warm, it avoids subprocess cold starts, and it spends the subscription budget through one session shape Anthropic actually optimizes for.
When I forced baro to use Claude Opus at max effort for every phase, it was slower: about 53 minutes. It also produced the most tests, which is not nothing. But it was not the practical winner. It was expensive in the resource that mattered: Claude session budget.
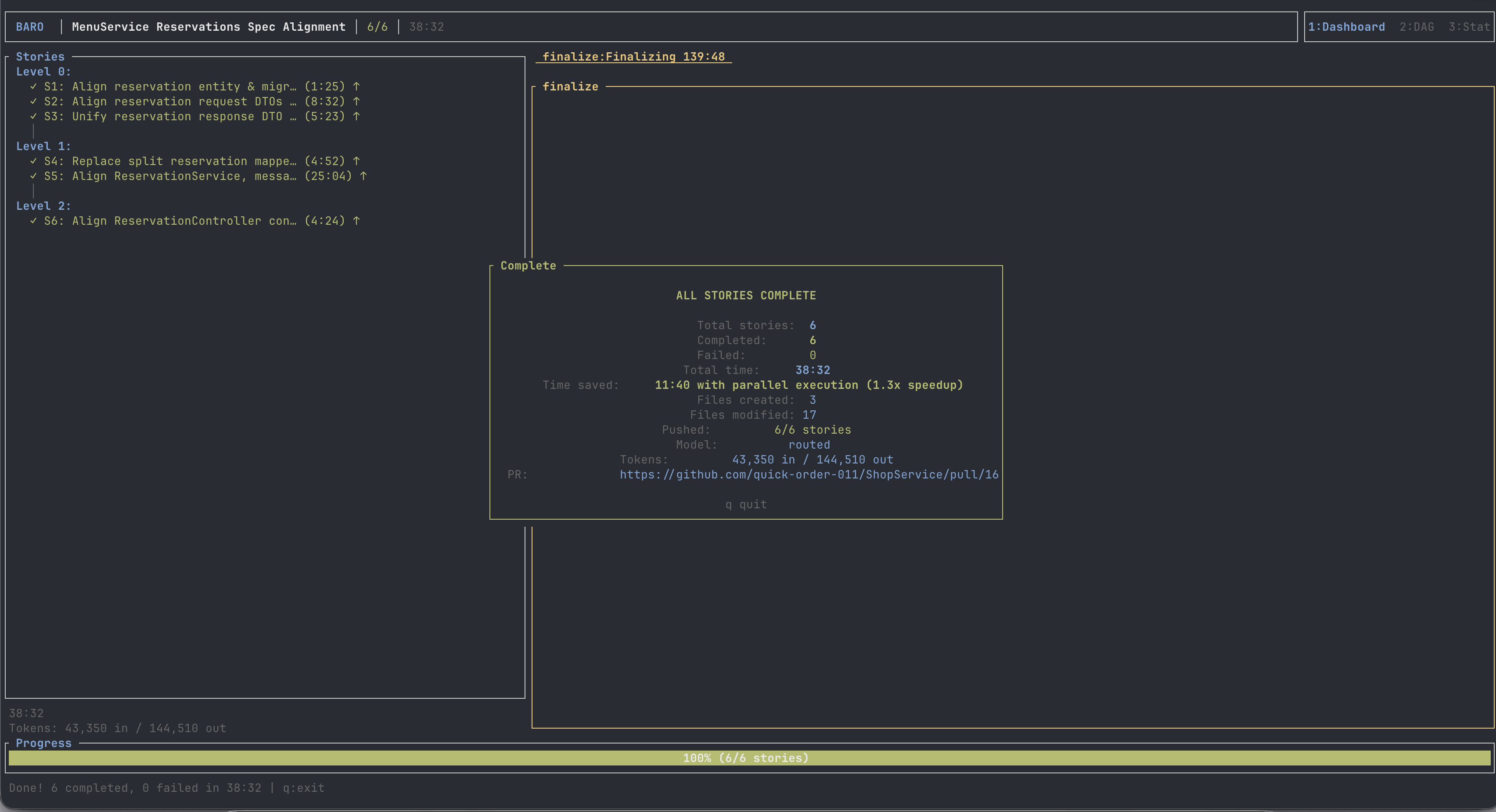
That is the first real lesson: parallelizing expensive Claude sessions multiplies expensive Claude sessions. If every story is a fresh claude --print process at max effort, the architecture is parallel, but the economics are bad.
What if I split the bill?
The hybrid run was the first time the shape clicked. Claude did the work I actually wanted Claude for: Architect and Planner. It read the repo, made the design calls, decomposed the feature into ten stories, and wrote the authoritative spec the workers would follow.
Then the stories ran on Codex. In my local Codex config that meant gpt-5.5 with model_reasoning_effort = "high". Not max. Not Claude. Just a capable execution backend pointed at a precise DAG.
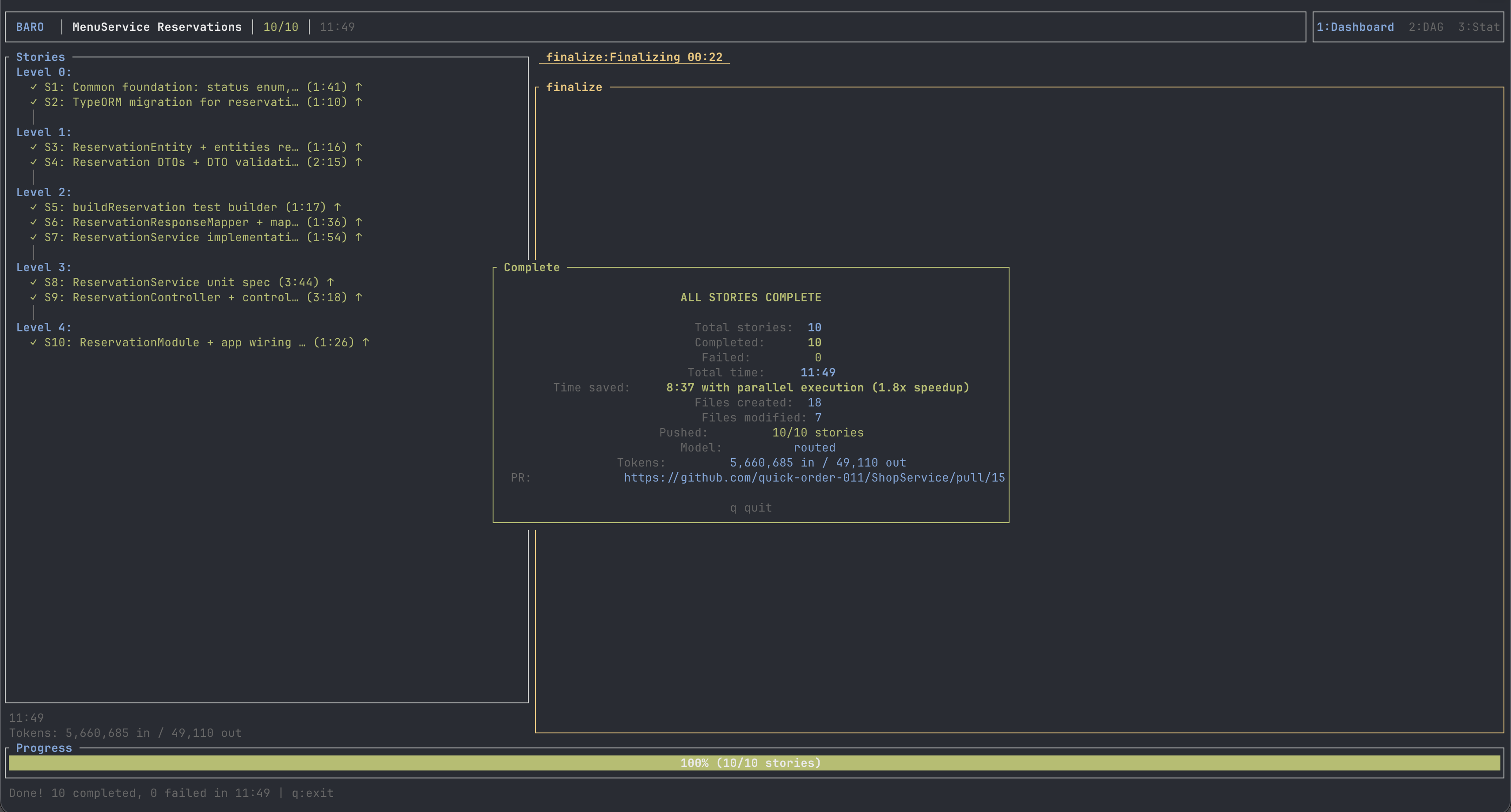
That finished the execution phase in 11 minutes and 49 seconds, opened a green PR, and did it without touching the Claude session bucket for story work. The total wall time was about 26 minutes including planning. At that point I thought the post was going to be about Claude for planning, Codex for execution.
Then I pointed the same DAG at DeepSeek.
Four cents
baro 0.47 added an OpenAI-compatible backend path. That means the same StoryAgent loop can talk to anything exposing a Chat Completions-compatible endpoint. DeepSeek was the obvious stress test: cheap, fast, and strict enough that bad tool-call formatting tends to surface quickly.
I reused the same Claude-authored DAG and ran the ten stories on deepseek-v4-flash.
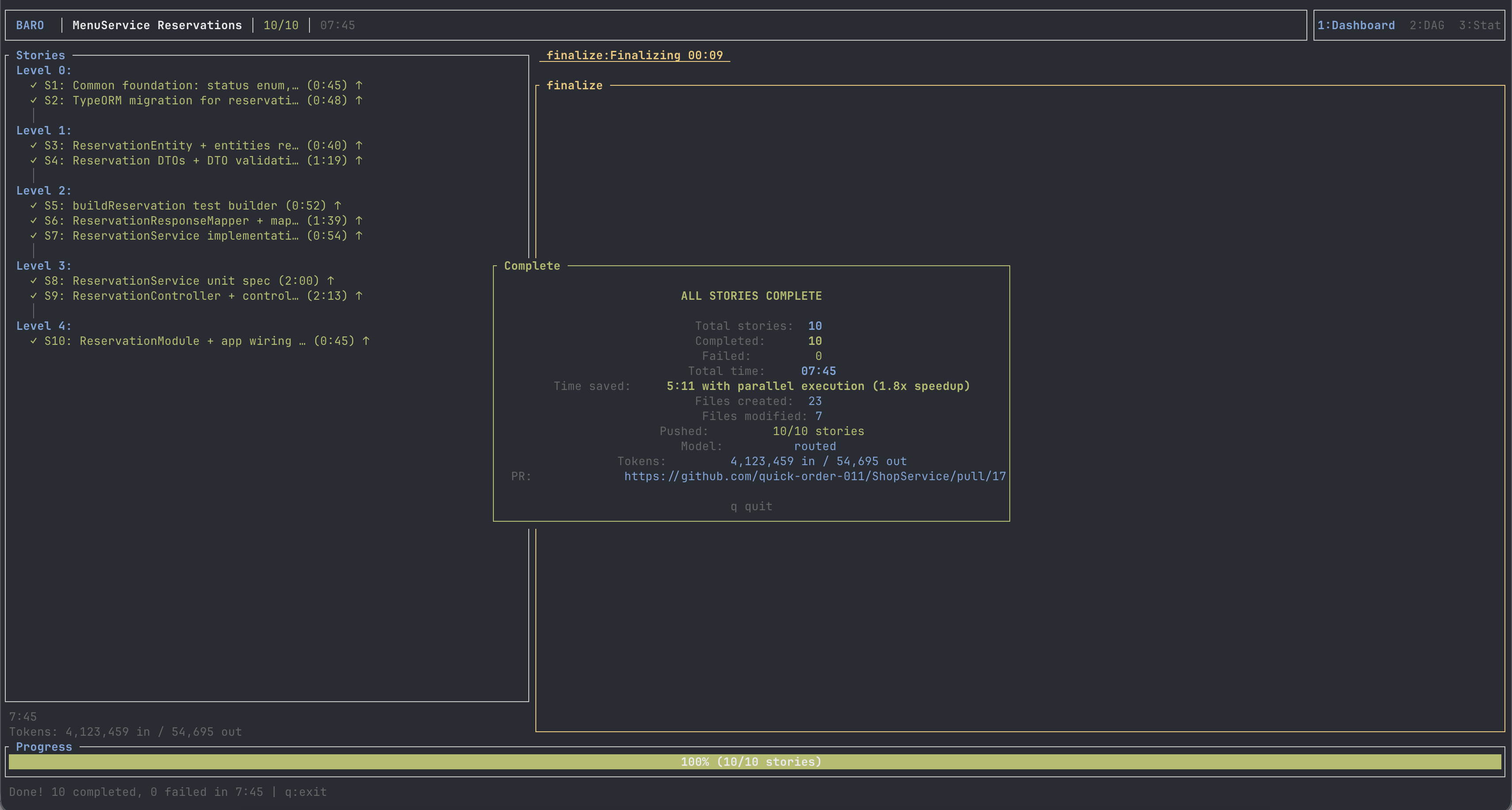
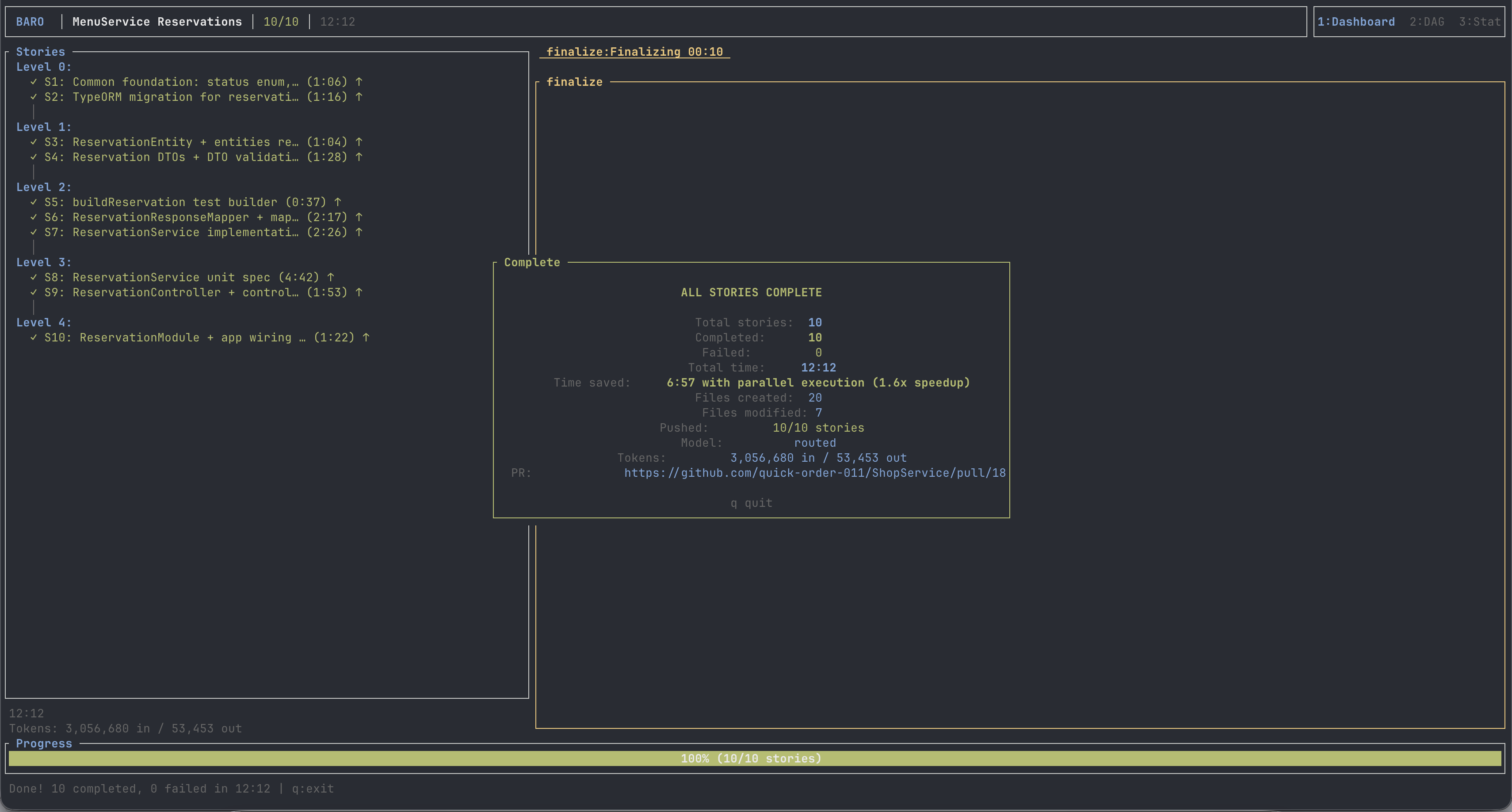
It finished in 7 minutes and 45 seconds. Ten out of ten stories passed. Zero retries. Build green. Full Jest suite green: 69 suites, 932 tests. The DeepSeek dashboard showed four cents.
The total is the headline, but the shape is the lesson — press play on the run above and you can watch it fire. Level 0 lays the foundation: the status enum (0:45) and the TypeORM migration (0:48). Levels 1 and 2 fan out — entities, DTOs, the response mapper, the service — four to seven agents writing at once. Level 3 is the bottleneck: the service unit spec (2:00) and the controller (2:13) cannot start until the things they test exist. That is why parallel execution saved five minutes against sequential — a 1.8× speedup — and also why it cannot save more. A DAG has a critical path, and you only go as fast as your deepest dependency chain.
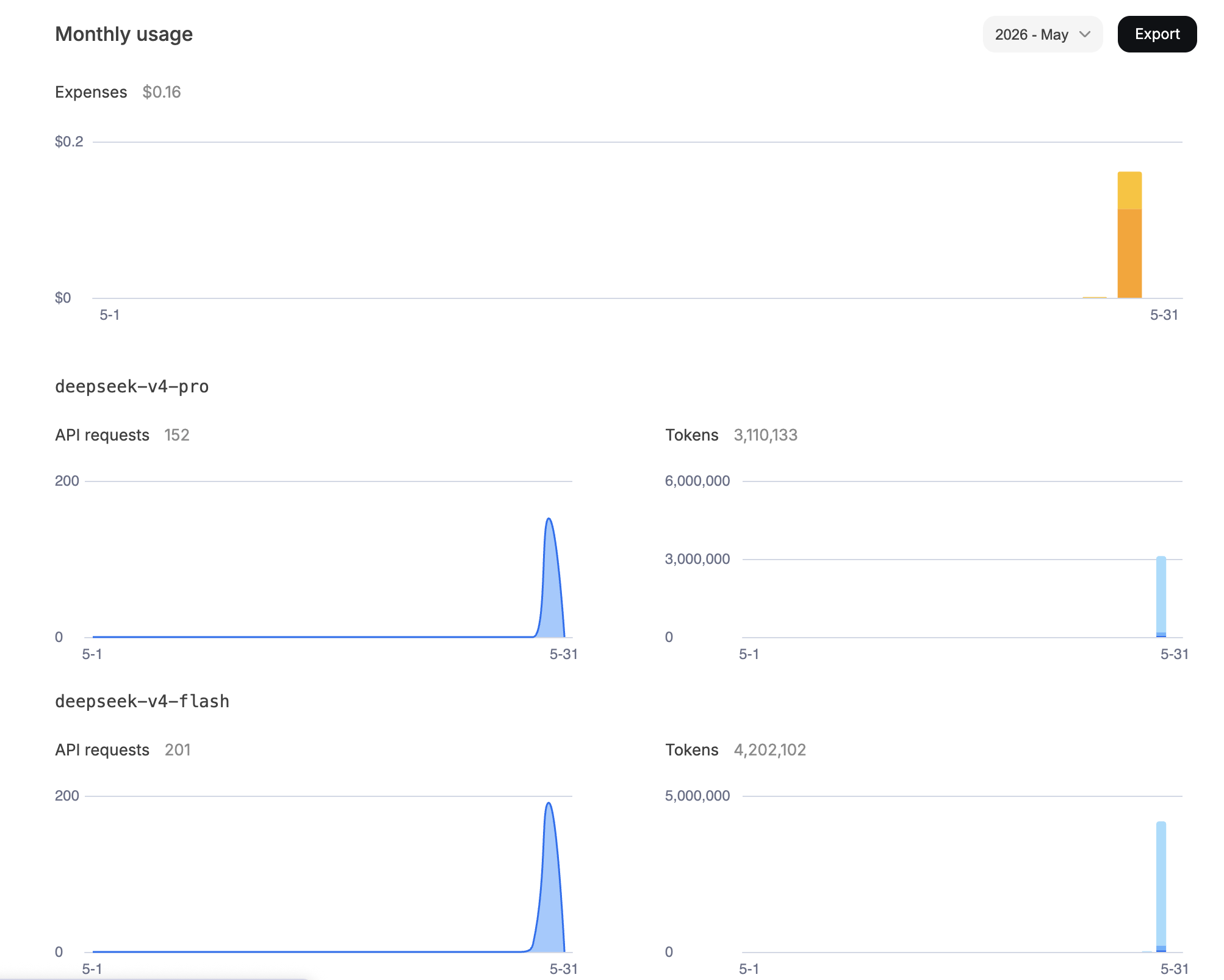
I ran deepseek-v4-pro next on the same DAG. It took 12 minutes and 12 seconds, also green, at eleven cents. Slower than Flash, cleaner than Flash in the PR hygiene, and still absurdly cheap for a full vertical backend feature.
Here are all five reservations runs side by side:
- Execution
- included
- Total
- 34m
- Cost
- Claude subscription
- Build + test
- 70 suites / 923 tests
- Diff
- 24 files, +2,306
- Execution
- 11m49s
- Total
- ~26m
- Cost
- ChatGPT subscription
- Build + test
- 69 suites / 905 tests
- Diff
- 25 files, +1,997
- Execution
- ~38m35s
- Total
- ~53m
- Cost
- Claude session-limit heavy
- Build + test
- 70 suites / 934 tests
- Diff
- 27 files, +2,266
- Execution
- 7m45s
- Total
- ~22m projected
- Cost
- $0.04
- Build + test
- 69 suites / 932 tests
- Diff
- 25 feature files, +2,272 / -2
- Execution
- 12m12s
- Total
- ~27m projected
- Cost
- $0.11
- Build + test
- 69 suites / 926 tests
- Diff
- 25 feature files, +2,303
Reservations is still a bounded vertical feature, though. Before I let four cents change how I think, I wanted to watch it survive a much bigger, messier task.
Does it hold at scale?
The reservations benchmark was useful, but it was still a bounded vertical feature. I wanted to know what happened when the DAG got wide enough that orchestration failures became part of the result. So I ran a second task on the same MenuService repo: build an Orders domain with order creation, item mutation, payment recording and refunds, kitchen tickets, status propagation, totals, migrations, controllers, and tests.
This was a 24-story plan. Claude Code ultracode ran it as one Claude Code workflow. baro ran the same kind of plan with Codex, DeepSeek V4 Pro, and DeepSeek V4 Flash as execution backends. It was large enough to expose the failure modes the smaller benchmark hid: blocked dependencies, failed story recovery, and the difference between a green test suite and a production-ready domain model.
- Time
- 62m
- Cost
- 55% Claude session
- Build + test
- 90 suites / 1,242 tests
- Diff
- 81 files, +10,105
- Time
- 45m45s
- Cost
- 11% Codex 5h sub
- Build + test
- 83 suites / 1,008 tests
- Diff
- 73 files, +6,396
- Time
- 41m31s
- Cost
- ~$0.62 marginal
- Build + test
- 83 suites / 1,207 tests
- Diff
- 79 files, +10,310
- Time
- 33m54s
- Cost
- $0.30
- Build + test
- 83 suites / 1,167 tests
- Diff
- 75 files, +10,344
The most interesting row is the last one. DeepSeek V4 Flash completed the 24-story Orders execution in 33 minutes and 54 seconds, with the full suite green, for thirty cents.
That number is not a merge recommendation. I reviewed the generated Orders PRs, and all of the large runs still needed human domain review. The recurring issues were exactly the kind you expect in a real backend: cross-shop protections, terminal-state immutability, kitchen-ticket invariants, and payment/refund edge cases. But that is also why the result matters. Thirty cents did not produce a perfect production patch. It produced a large, compiling, tested backend implementation that was good enough to review.
The four-cent question
Four cents did not buy me a toy completion. It bought a green PR for a real NestJS feature: entity, migration, DTOs, mapper, controller, service logic, tests, no-overlap rules, capacity checks, lifecycle transitions, and the full existing Jest suite still passing. The Orders task made the same point with a noisier, more realistic workload, for thirty cents.
I do not know DeepSeek's true marginal inference cost. Public API pricing is not a physics constant. It includes strategy, subsidies, capacity allocation, competition, and whatever a provider wants the market to believe this work is worth. But I do know the price I was charged, and I know what came out of it. That is enough to change how I think about agent architecture.
Claude is expensive because it earns a premium in places where ambiguity is high: reading a messy repo, deciding where the seams belong, choosing a plan, catching subtle mistakes, and recovering when the task goes sideways. That does not mean every migration, DTO, mapper, and controller test should pay the same premium.
The expensive mistake is not using Claude. The expensive mistake is using Claude everywhere.
That sentence changes the benchmark. The fastest successful run was not the biggest model. It was not the largest context window. It was not the purest multi-agent architecture. It was a premium planning model producing a precise DAG, followed by a cheap execution model doing bounded work in parallel.
Before running this, I was still half-thinking about agent systems as model competitions. Claude vs Codex. Codex vs DeepSeek. Pure-Claude vs hybrid. That framing is too small. The useful unit is not the model. The useful unit is the phase. Planning is not execution. Reviewing is not migration-writing. Controller wiring is not status-transition design. A coding DAG gives you boundaries, and once you have boundaries, you can price them differently.
That is the economics of parallel coding agents: parallelism is only half the story. If you parallelize work across the same expensive session budget, you can make the budget disappear faster. If you parallelize work into well-scoped stories and route each phase to the backend that makes sense, the cost curve changes.
What I'd actually run
If you remember one thing
- Plan with Claude (Architect + Planner). Pay the premium where ambiguity is highest.
- Execute on the cheapest backend that clears the acceptance bar. For bounded stories that is usually not a frontier model.
- Escalate only the risky stories — or reruns of failed ones — to a stronger model.
Concretely, for a real run today I would not start with pure-Claude max. I would start with something like this:
OPENAI_API_KEY="$DEEPSEEK_API_KEY" \
baro --llm hybrid \
--story-llm openai \
--openai-base-url https://api.deepseek.com \
--story-model deepseek-v4-flash \
"Add a complete reservations module"For riskier stories I would route only those to Pro, or rerun failed stories on Pro. For architecture-heavy planning I still want Claude. For broad mechanical execution, I no longer think the premium model should be the default.
What this says about baro
The honest result is not "baro beats Claude Code." Claude Code was the better pure-Claude workflow in this test. It deserves that credit.
The stronger result is that baro lets the unit of routing be smaller than the whole coding session. It can spend Claude on the part where Claude earns it, then spend Codex or DeepSeek on the parts where they are good enough, faster, or dramatically cheaper.
The best architecture was not the one that used the strongest model everywhere. It was the one that let me choose.
That is the post I did not expect to write. I thought I was benchmarking parallel coding agents. I ended up benchmarking the price of not having a routing layer.
baro is on npm and GitHub. The event bus underneath it is Mozaik.
If this kind of agent architecture is interesting to you, join us in the JigJoy Discord. We talk a lot about baro, Mozaik, event-based reactive agents, model routing, and what actually happens when you try to run this stuff on real codebases.
You can also follow or DM me on X / Twitter if you want to compare notes, argue with the benchmark, or talk about parallel coding agents.

Different is better than better.
Made with baro, several confused benchmark runs, and less than one dollar of DeepSeek.
