Getting the Maximum Out of My Claude Code Subscription

I have Claude Code Max. Last quarter, I was using maybe twenty percent of my quota.
Not because the subscription is too generous — it's not. Because Claude Code is designed for one human, one terminal, one conversation at a time. You type, you wait, you read the diff, you type again. While you read, while you think, while you're in a meeting, while you sleep — your subscription is paying for inference that's sitting idle.
The fix looks obvious: run more sessions in parallel. Anthropic just shipped a --worktree flag for exactly this — five terminals, five branches, five Claude sessions, side by side. Most days, that's still one human supervising five sessions. Better than one terminal. Still you, watching.
What I wanted was a thing I could hand a goal to, walk away from, and come back to a pull request. No babysitting. Five Claude sessions reading my codebase, splitting the work between themselves, reacting to each other's findings, reviewing each other's output, and pushing a PR when they're done.
I built a few versions of that thing before I got it right. The first two collapsed under their own weight. The third works.
It's called baro. It's a CLI you install from npm — you point it at a goal, walk away, and come back to a pull request. About 6,600 developers have installed it so far. This is what changed.
The bottleneck isn't the model
Here's the strange thing about pair-programming with Claude Code. The model isn't the slow part. Anthropic ships a model that can plan a feature in seconds and write a thousand lines of correct code in minutes. The slow part is me. I have to read the diff, decide if I trust it, ask for changes, re-read, ask again. While I do that, the model is idle. The session is idle. My subscription quota is idle.
Multiply that by every meeting, every coffee, every focus block where I'm not actively in Claude Code, and the picture gets sharper: the cost per useful minute of my subscription is way higher than it should be. I'm paying for a horse and walking it on a leash.
The fix has to be parallelism — but not the kind that makes my eyeballs the bottleneck five times over. I need parallelism out of my supervision. Sessions that spawn themselves, do their thing, and check back in when there's a PR to review.
First attempt: a Promise.all of Claude subprocesses
The first version was the obvious one. I wrote a TypeScript script that:
- Asked Claude (Opus) to break the goal into a DAG of stories.
- For each level of the DAG, spawned one
claudeCLI subprocess per independent story, in parallel. - Awaited
Promise.all. - When the level finished, ran a review pass over the diffs, kicked off fix stories if needed, and moved to the next level.
// What the orchestrator looked like before Mozaik
async function run(prd) { for (const level of prd.levels) { const results = await Promise.all( level.stories.map(s => runStory(s)) )
const fixes = await reviewer(results) if (fixes.length) { await Promise.all(fixes.map(runStory)) } }
await commitAndPush() await openPR()}It worked. Sort of. The pull requests came out. But living with this code for a few weeks, every problem with the design surfaced, one at a time:
- No cross-agent memory. Story A reads
package.jsonto figure out the build tool. Story B does the same five seconds later. Both pay for the read. They're working on the same repo and they don't share a single byte. - No mid-flight reaction. Story C decides to write tests in the wrong place. The orchestrator can't tell. It only sees the final diff, after which it's too late to gently redirect — the only knob is "kill and retry."
- State is scattered across closures. A crash mid-run means starting over. There's no replay log, no resumable PRD, no audit trail.
- Adding any new responsibility means surgery. Want timeouts? Edit the orchestrator. Want conflict detection on overlapping file writes? Edit the orchestrator. Want a JSONL log of everything? Edit the orchestrator. Every cross-cutting concern collides in the same
run()function.
Promise.all gave me parallel execution. It didn't give me an agentic system. It gave me threads with extra steps.
Second attempt: git worktrees and five terminals
Anthropic recently shipped a --worktree flag for Claude Code. The popular pattern around it goes like this: spin up a tmux pane per terminal, give each one a claude -w session on the same repo, hand each one a different feature, and let them work in isolated branches. There are good blog posts and skills built around it.
I tried this pattern. It is genuinely better than one terminal. You can be writing tests in pane two while pane one is refactoring your auth layer.
But it's not what I wanted, either. The reason is the same: I'm still the orchestrator. I decompose the goal into stories. I pick which terminal gets which story. I read each session's output. I notice when one is going off the rails. I merge five worktrees back into a single branch. I open the PR.
Five sessions, one human, plus a stopwatch. The token bill goes up roughly 5×. My eyeballs do not get any faster.
Worktrees solve isolation. They don't solve coordination. They don't decompose the work for you, they don't let agents share what they've learned about the codebase, they don't review each other's output, and they can't tell you when two stories are about to collide on the same file.
I needed something that could.
What about subagents, /loop, Ralph?
Three patterns kept coming up while I was building this. Each is a real tool. None of them is what I needed.
Claude Code subagents. You spawn a subagent from your main session, it does a focused thing, returns one result, exits. Excellent for parallel exploration ("search the codebase ten different ways at once") or isolated heavy-context work. But every subagent is fed the parent's context, which is why subagent-heavy runs use roughly seven times the tokens of a single thread. And critically: subagents serve the parent. They don't run unrelated workstreams in parallel. They don't put up their own PRs.
The /loop slash command. A session-level scheduler that reruns a single prompt at an interval. Perfect for "every five minutes, check whether the deploy finished" kind of work. It's a cron, not a coordinator — one Claude, one prompt, on repeat. Sequential. Not what helps when you have ten unrelated things to ship.
Ralph (Geoffrey Huntley's Ralph Wiggum loop). A bash one-liner:
# Ralph (Geoffrey Huntley): vertical persistencewhile :; do cat PROMPT.md | claude-code; doneClaude reads a prompt, does one step, edits the prompt to track its own progress, exits. Loop runs again with the updated prompt. Brute-force persistence — Huntley famously left it running for three months and produced a working programming language. It's a beautiful pattern, and Anthropic has even shipped it as an official plugin.
But Ralph is vertical parallelism: one agent, going deeper and deeper on one prompt until it dreams up the answer. baro is horizontal parallelism: many agents, going wide on independent stories at the same time. Different axes. They aren't competitors. The agentic system I'd actually want has both — Ralph for "keep trying until this is right," baro for "do all of these at once." You can imagine a Ralph loop that lives inside one of baro's stories. They would compose.
But for the work I had — fifteen open issues by Friday — Ralph wasn't the answer. baro is.
Mozaik: agents on a shared bus, not in a shared context
The shape I wanted was a system where agents could coordinate without sharing a context window. Sharing a context window is exactly what subagents do — and exactly what makes them expensive and tightly coupled. What I wanted was for agents to coordinate by what they did, not by what they remembered.
Mozaik (GitHub) is a TypeScript runtime for agentic environments. Its core abstraction is exactly that: agents (Mozaik calls them participants) emit and subscribe to typed events on a shared bus. There's no parent context to inherit. Each participant has its own state, its own scope, its own job. They communicate by what's on the bus, not by what's in memory.
The concrete shift, in baro, was tiny on paper and huge in practice:
- The Conductor doesn't have a
run()method. It has anonContextItem(item)handler that reacts to events. - When the Conductor sees a
RunStartRequest, it emits aLevelComputeRequest. When a StoryFactory participant sees that, it spawns Story Agents. Each Story Agent is a top-level Claude CLI subprocess — full context window, no parent thread. - When a Story Agent finishes, it emits a
StoryResult. The Critic and the Conductor both see that event independently and react.
// What it looks like now: a Mozaik participant
class Conductor extends Participant { onContextItem(item: ContextItem) { if (item.type === "RunStartRequest") this.emit(LevelComputeRequest())
if (item.type === "StoryResult") this.checkLevel(item)
if (item.type === "LevelCompleted") this.emit(this.nextLevelOrFinish())
// no run(), no while, no Promise.all }}Three small architectural choices. Together they unlocked everything I'd been failing at.
What baro does now
Here's a real run, condensed. The command:
# install oncenpm install -g baro-ai
# point it at a goal, walk awaybaro "Add JWT authentication with role-based access control"Claude Opus reads my codebase and emits a plan: five stories with dependencies. I approve it. Three independent stories light up at once on a fresh baro/jwt-auth branch — auth-types, auth-middleware, role-policy — each in its own Claude Sonnet subprocess.
The Librarian, another participant on the bus, watches every tool call. When auth-types reads my package.json and runs a grep for existing auth code, the Librarian indexes the findings. By the time auth-middleware starts, its prompt has already been augmented with what auth-types learned. No duplicate exploration. No wasted tokens.
The Sentry watches Edit and Write tool calls. If two concurrent stories are about to collide on the same file, it surfaces a warning on the bus before the merge conflict has a chance to happen.
When the level completes, the Critic — running on Haiku — reads the diffs and votes. If a story missed its acceptance criteria, the Surgeon emits a ReplanItem and the Conductor recomputes the DAG at the next level boundary. Maybe it drops the failing story. Maybe it splits it into smaller pieces. The orchestration responds.
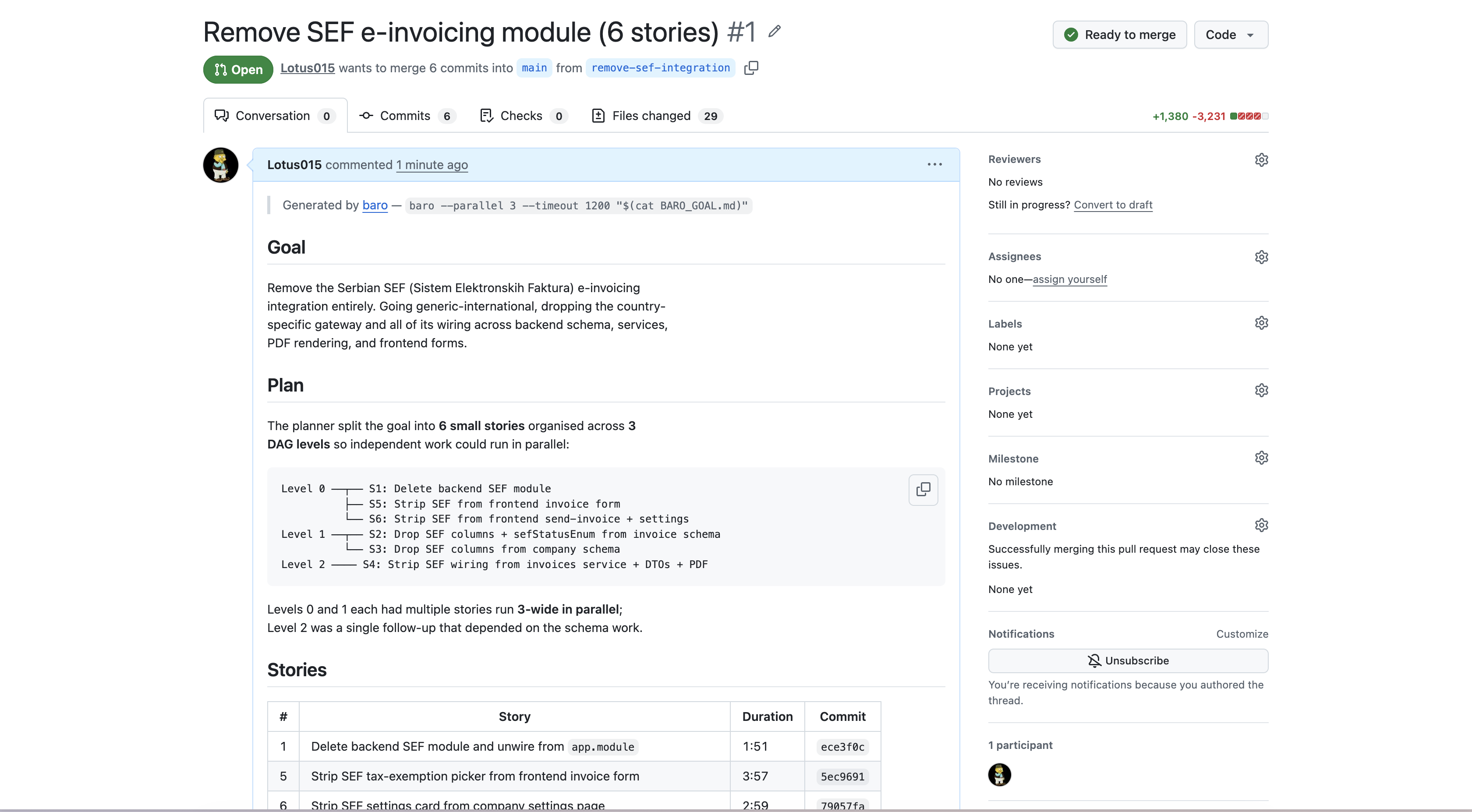
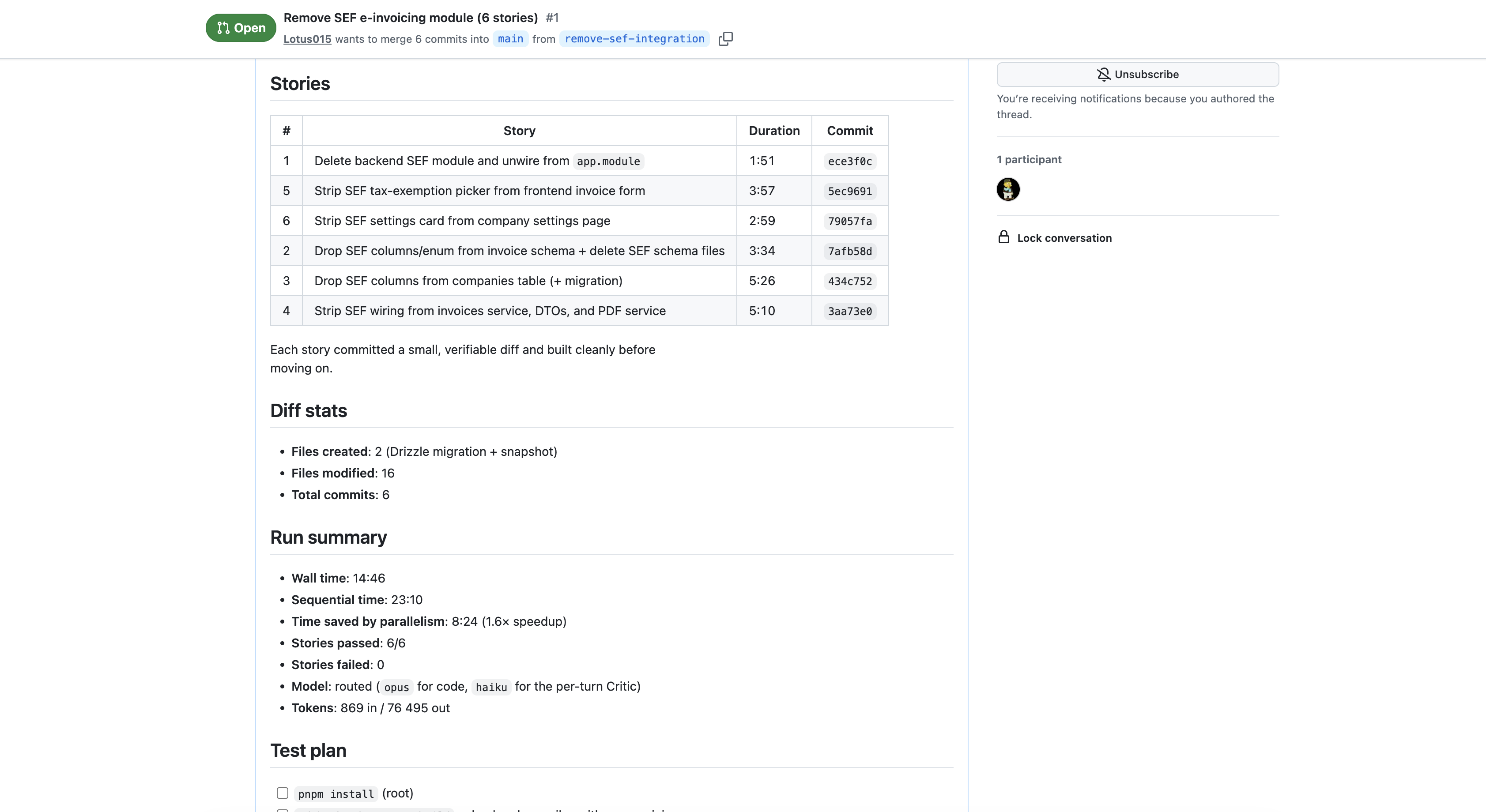
Two more stories run on the second level (auth-routes, auth-tests). They depend on the first three. The Operator handles git: the feature branch, the commits, the rebase. At the end, baro pushes and opens a pull request, including a stories table, build verification stats, and the time I just saved versus running everything sequentially.
The thing I want you to notice: I didn't supervise any of that. I started the run before lunch. When I came back, there was a PR waiting for me to review.
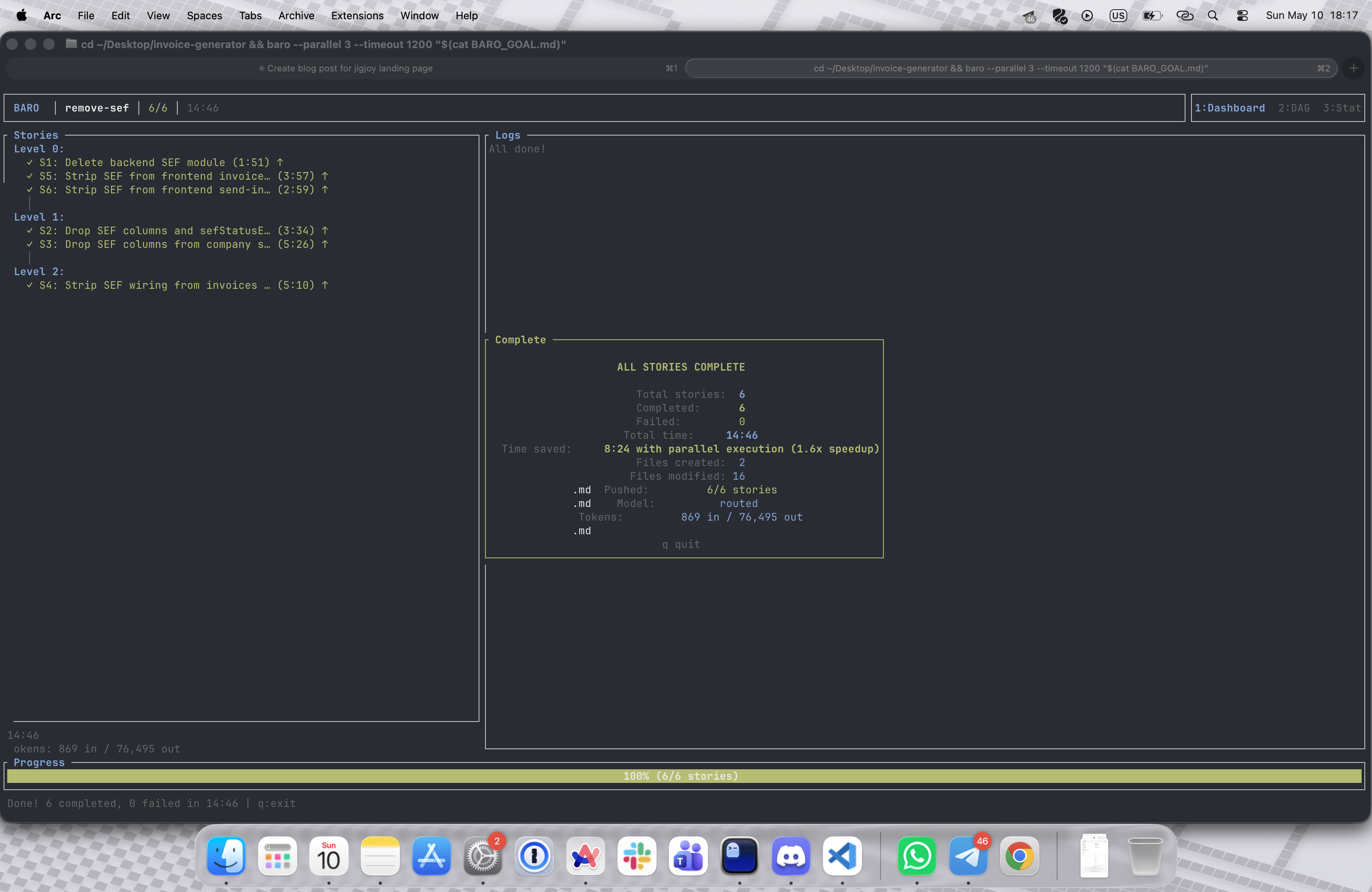
Below: a real run from earlier today. Six stories to strip a country-specific e-invoicing module out of a NestJS + Next.js monorepo, run with baro --parallel 3. The TUI on completion, the pull request baro opened, and the stories table it generated.
The bus is open
Here's the part that I think makes Mozaik more than an implementation detail.
The bus is open. Anyone can write a participant. baro ships ten of them — Conductor, Story Factory, Story Agent, Critic, Surgeon, Librarian, Operator, Sentry, Auditor, Cartographer — but the architecture doesn't care that those are the only ten.
A participant is a class with an onContextItem handler and an emit method. If you want a CI participant that subscribes to RunCompleted events and triggers a deploy: that's about fifty lines of TypeScript and zero changes to baro. A Slack participant that posts story-status updates to a channel as StoryResult events fly by? Same. A monitoring participant that pings Datadog when level transitions are slow? Same.
It also goes the other way. A participant can listen to the outside world and emit into the bus. A webhook receiver that turns a "Linear ticket created" event into a RunStartRequest would let baro start a coding run because someone filed a ticket. A GitHub-issue listener could do the same for good first issue-labeled tickets. A Datadog alert listener could trigger a fix story when the SLO error rate climbs.
baro today does one thing: takes a goal and pushes a PR. The shape of the system underneath it is a kernel for an agentic surface that reacts to the rest of your stack — deployments, tests, monitoring, ticketing, on-call. None of those are baro's job. All of them could be participants on the same bus.
baro is the proof that the kernel works. The rest is participants we haven't written yet.
Try it



Open source on GitHub at jigjoy-ai/baro, published on npm as baro-ai. MIT license. Auth inherits from your existing Claude CLI session — no API key, no separate billing, just your Claude Code subscription doing more work than one terminal can fit.
Quick start
# 1. Make sure Claude Code CLI is installed and you're logged inclaude --version
# 2. Install baro globally from npmnpm install -g baro-ai
# 3. Go to the repo you want baro to work oncd path/to/your/repo
# 4. Hand it a goal and walk awaybaro "Add rate limiting to all API endpoints"
# baro plans the work, spawns Claude sessions in parallel,# pushes a branch, and opens a pull request when it's done.I built it because I was tired of paying for inference I wasn't using. If that's you too, give it a goal and walk away. See what comes back.
Heads up: baro is very much a work in progress. I'm still experimenting with it, adding new participants, testing new ideas, and sometimes things break. If you like where this is going and want to help build it — PRs, issues, and harsh feedback are all welcome on GitHub. If you have ideas on how to make it better, ping me on Twitter / X — I read every DM.

With tools and technology we already have, we can build much more valuable systems than most projects today. We can write software that is a pleasure to use and a pleasure to work on; software that doesn't box us in as it grows, but creates new opportunities and continues to add value for its owners.
Made with baro itself. 🤖
