Not Every Task Deserves Parallel Agents

I built baro for myself. My tasks decompose: a schema story here, a service story there, three UI stories that never touch the same file. Fan out a DAG of agents, let them work in parallel worktrees, merge, ship. Most of my week looks like that, so that is what I built — and parallel execution was not a feature of baro, it was the premise.
Then baro started getting real users, and I started slowly losing my mind.
The bugs were trying to tell me something
The reports came in fast once people actually used the thing daily. Each one looked like a separate bug. I fixed them like separate bugs. It took me an embarrassing number of them to see the pattern.
A user ran a follow-up on an existing PR — a bugfix, the kind of thing you'd hand to one agent with one sentence. baro's planner shredded it into five stories, spun up five agents, and burned 5.2 million input tokens splitting work that had no seams to split along. Five agents editing around one shared surface is not parallelism, it is a merge conflict generator with a token bill.
Another user pasted a bare PR URL as the goal. baro interpreted it as "review and integrate this PR", discovered mid-run that the PR was already merged, and pivoted to fixing unrelated compile errors in the repo — 1.8 million tokens into a task nobody asked for. It never stopped to say: this input is vague, and the safest interpretation is a small one.
Meanwhile our preview runs were trying to push branches from clones that deliberately had no remote, spraying GH_TOKEN missing errors into logs, and PR diffs were arriving polluted with baro's own working artifacts — prd.json, ADR files, a regenerated lockfile — on top of the user's actual change.
The pattern: baro had exactly one shape of run — mine — and it was imposing that shape on everyone's work.
Most of what a working developer does in a day is not a parallelizable epic. It is a bugfix. A follow-up. A rename. A small feature that touches one module in three ordered steps. For those tasks, a DAG fan-out is not just overkill — it is actively worse than doing nothing clever at all. If baro was going to be anyone's daily driver, it needed the other shapes too, and it needed to pick between them without being told.
Intake: deciding the shape before the first agent spawns
So we built an intake step. Before planning starts, baro classifies the goal into one of three execution modes:
- focused — one story, one strong agent. Bugfixes, follow-ups, anything centered on a single surface.
- sequential — a few ordered stories, one agent at a time. Stepwise work on shared code.
- parallel — the full DAG fan-out, but only where independent write surfaces can actually be demonstrated.
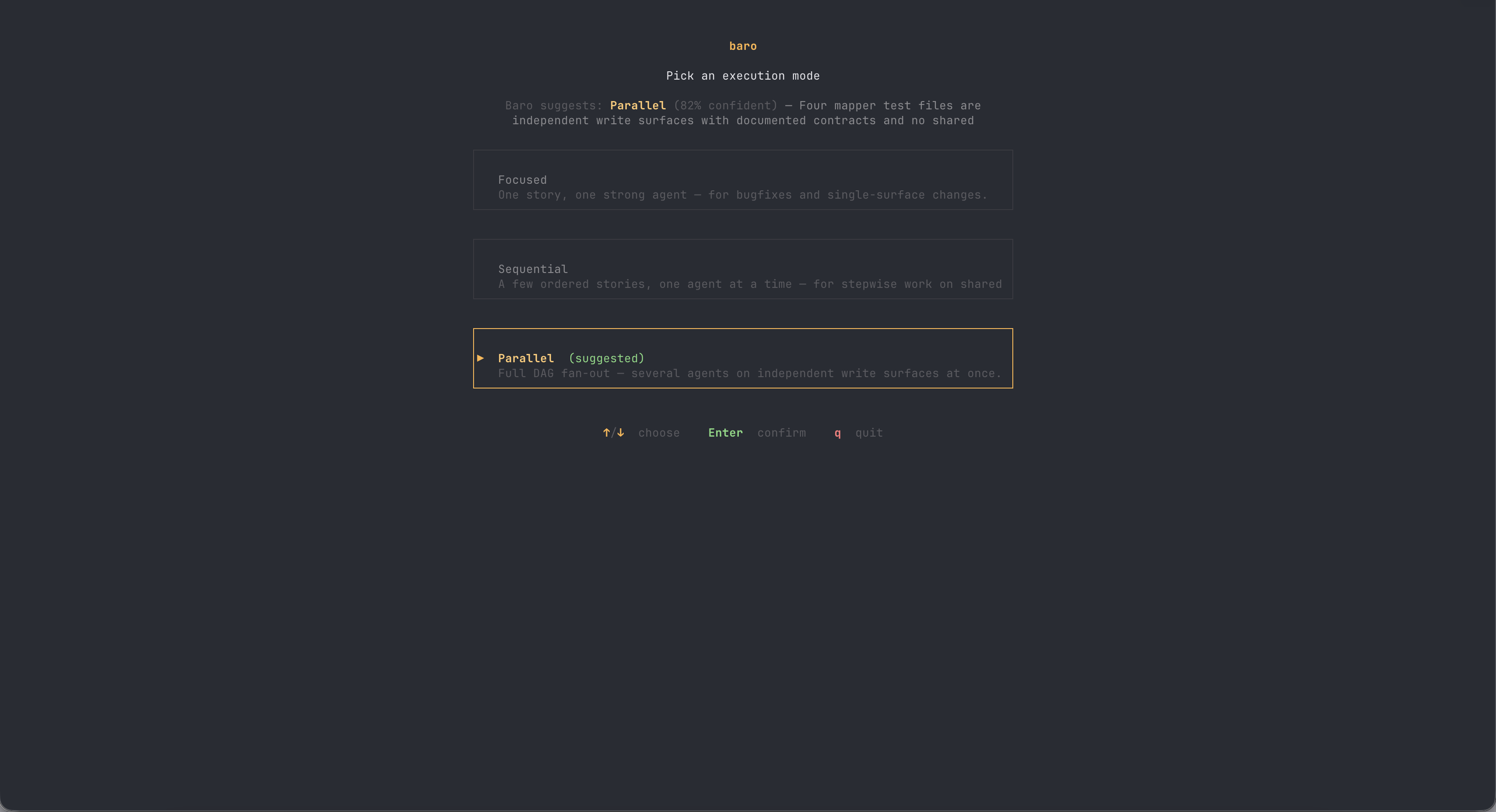
The classification comes back with a confidence and a reason, and in the CLI you see it as a picker — accept the suggestion with Enter, or override it with the arrow keys. You stay in charge; baro just stops making you pay for its default assumption.
The part I care most about: the decision is enforced in code, not suggested in a prompt. We tried the polite version first — a planner prompt block saying "please output exactly one story" — and watched a model cheerfully emit five anyway. Now, if intake says focused and the planner still fans out, the orchestrator collapses the plan to a single story. Story caps are hard caps. Parallelism limits are enforced by the conductor. An LLM's opinion of its own restraint is not a contract; the code is.
All of this is in baro 0.70.15 — npm install -g baro-ai and the picker is the first thing you see after typing a goal.
To prove it does what it says, I ran two real tasks from baro's own backlog — on baro's own repo, with the Codex backend, from the terminal. Not demo tasks: both PRs are open on the public repo.
- Plan
- 1 story
- Execution
- 1 agent
- Wall clock
- 2:32
- Tokens
- 373k in / 4.6k out
- Diff
- 1 file, +2 / −2
- Proof
- PR #67
- Plan
- 4 stories, one level
- Execution
- 4 agents at once
- Wall clock
- 5:20 (11:14 saved, 3.3× speedup)
- Tokens
- 1.88M in / 29.7k out
- Diff
- 4 new test files, +1,029
- Proof
- PR #68
Run one: the focused fix (and an honest admission)
The goal was a genuine annoyance: a finalizer test failing on main since a recent refactor. I typed one sentence — fix it, and figure out whether the test or the implementation is wrong — and left the mode on Auto.
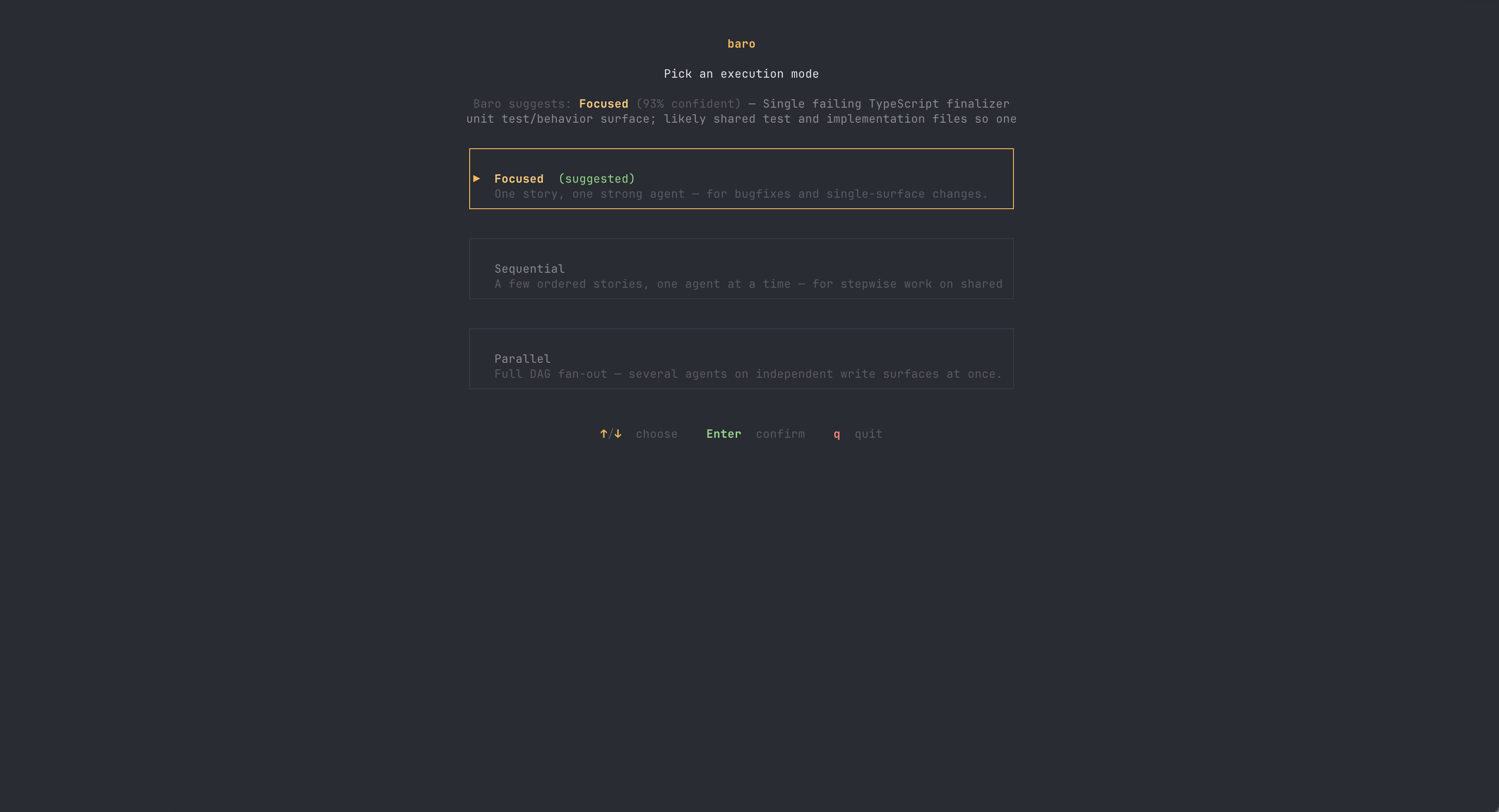
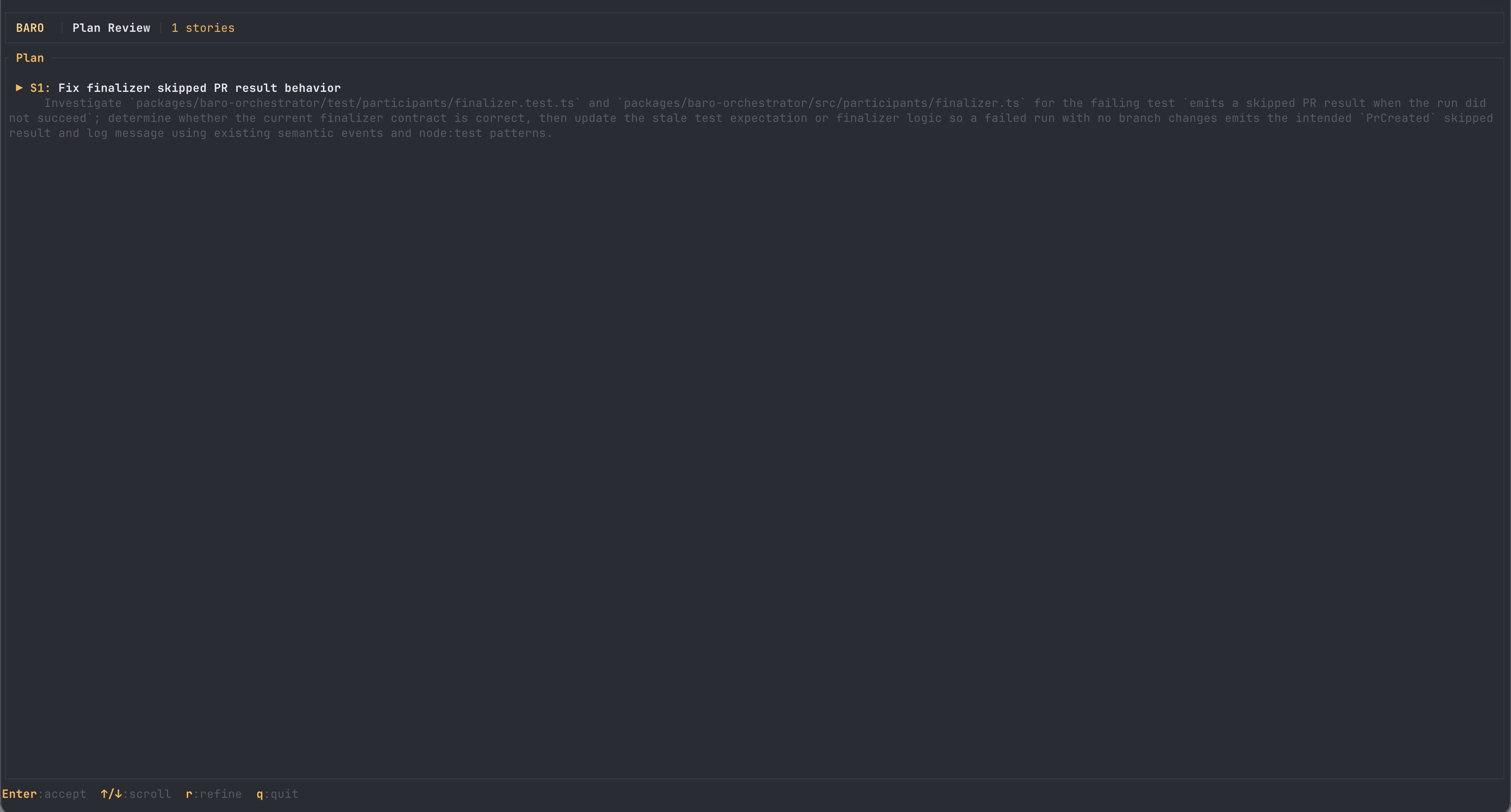
Intake said: focused, 93% confident — "single failing TypeScript finalizer unit test/behavior surface." One story in the plan. One agent in the run. The agent read the test and the implementation, concluded the test's expectation was stale rather than the finalizer being broken, and changed two lines.
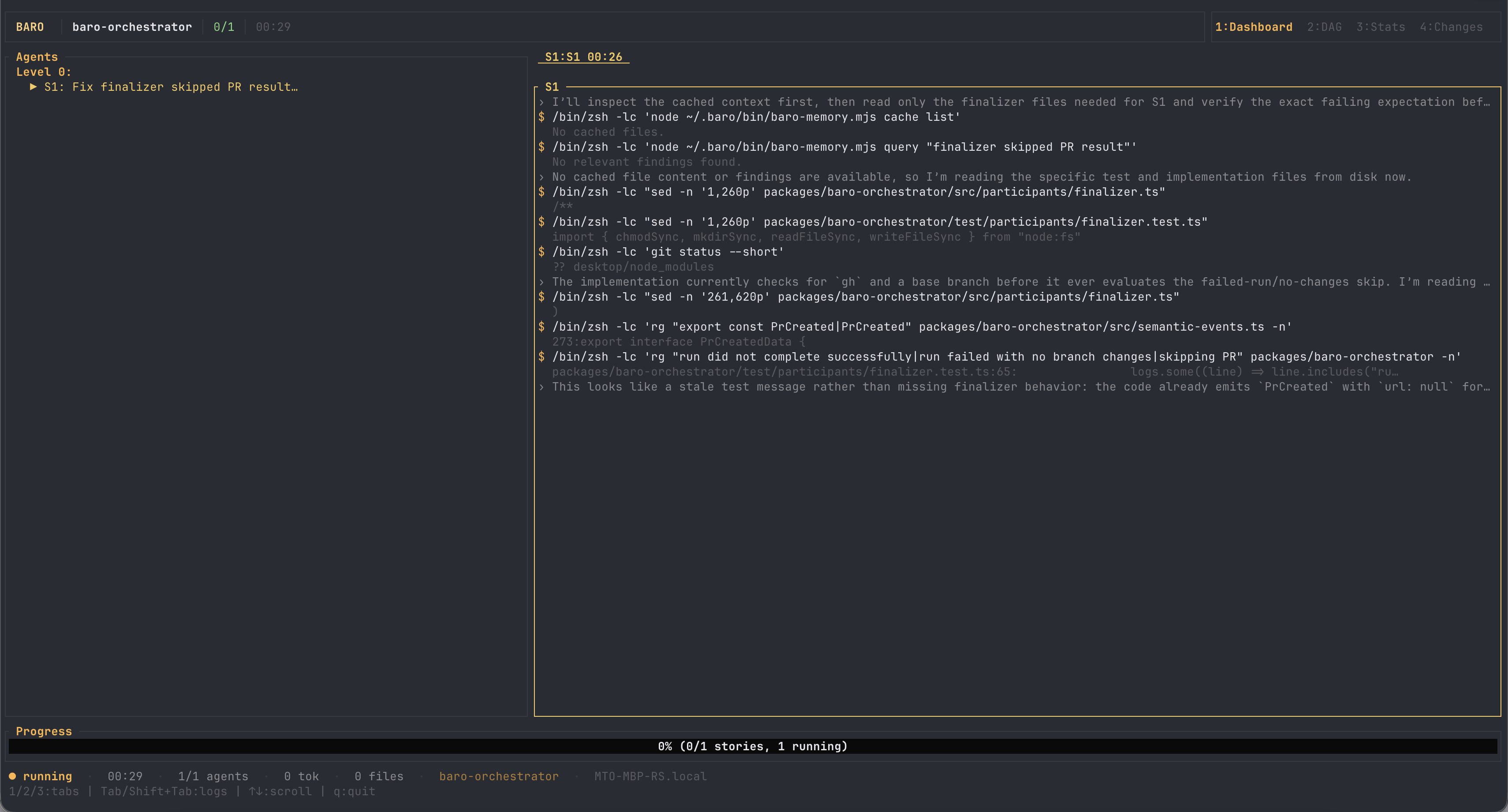
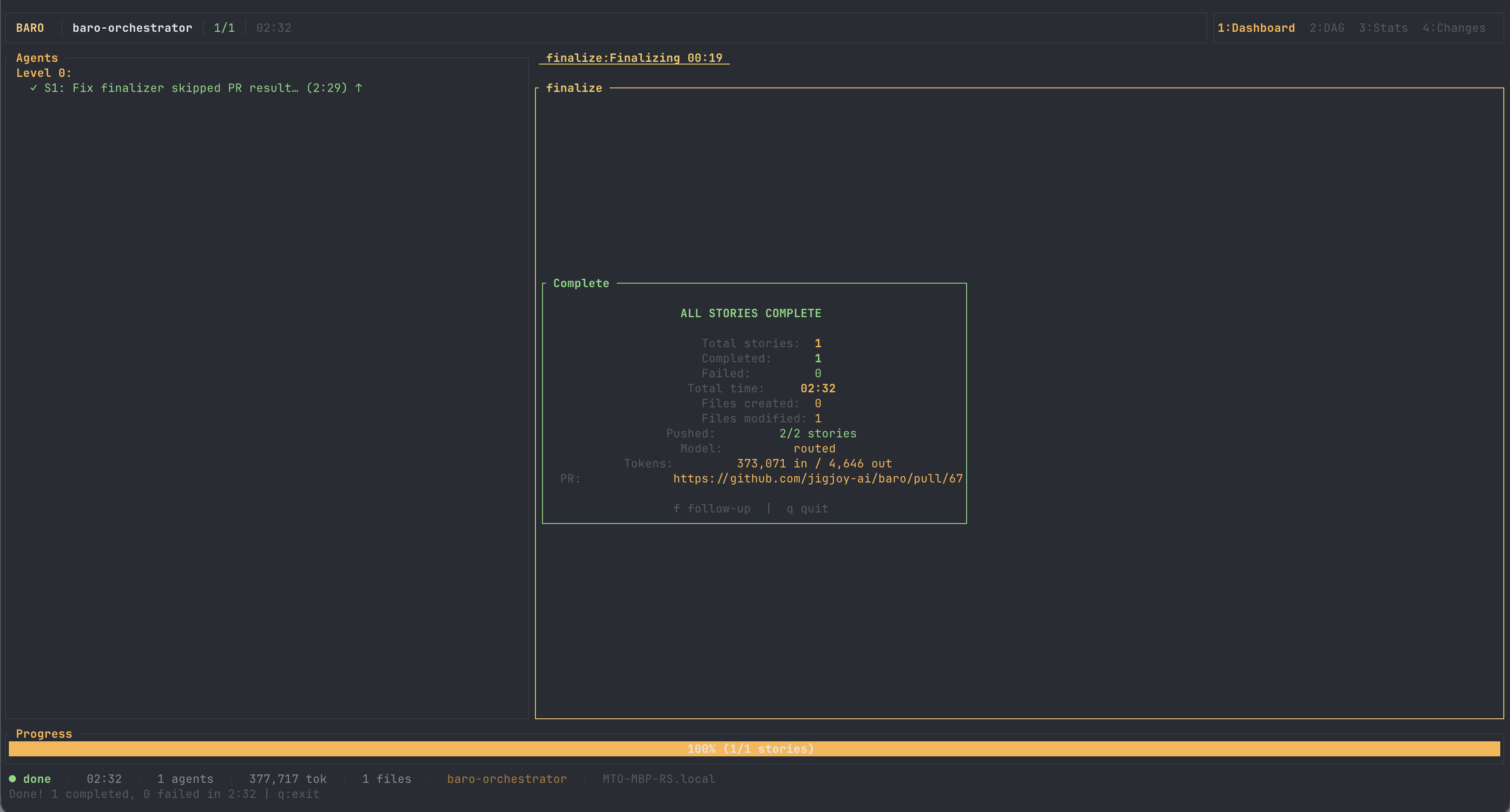
Two minutes thirty-two. One file. +2/−2. A clean PR with none of baro's own artifacts in the diff. Here it is.
Now the honest part: a plain Claude Code or Codex session would have done this task just as well, possibly better. One agent reading two files and fixing an assertion does not need an orchestrator, a DAG, worktrees, or a merge strategy. If your whole day is tasks like this one, baro is not the tool that changes your life, and I would rather tell you that than pretend otherwise.
What matters is what did not happen. Six weeks ago this exact goal would have become three to five stories, several agents, a seven-figure token count, and a diff with five authors of one idea. The win in focused mode is not that baro is better than a single agent — it is that baro now knows when to be a single agent.
Run two: where the fan-out earns its keep
Second goal, also straight from the backlog: none of baro's four backend stream mappers — the modules that translate Claude, Codex, OpenCode and Pi wire events onto our bus — had any test coverage. Four protocol-critical modules, four separate files, wire formats already documented. I typed the goal and left the mode on Auto again.
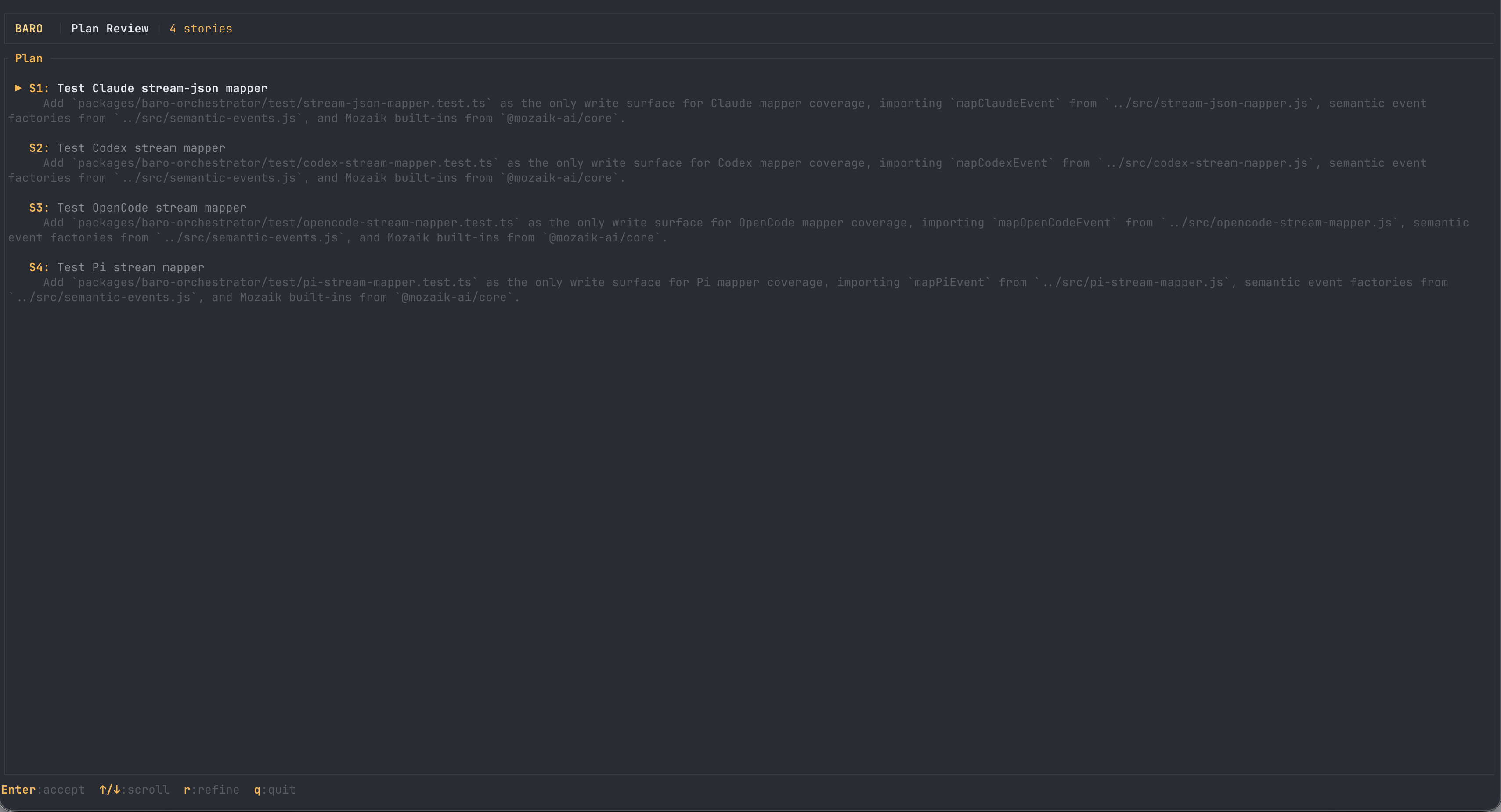
Intake said: parallel, 82% confident — "four mapper test files are independent write surfaces with documented contracts." And look at the plan it produced: each story names its one write surface explicitly. That is the condition for safe parallelism, stated as part of the plan instead of hoped for.
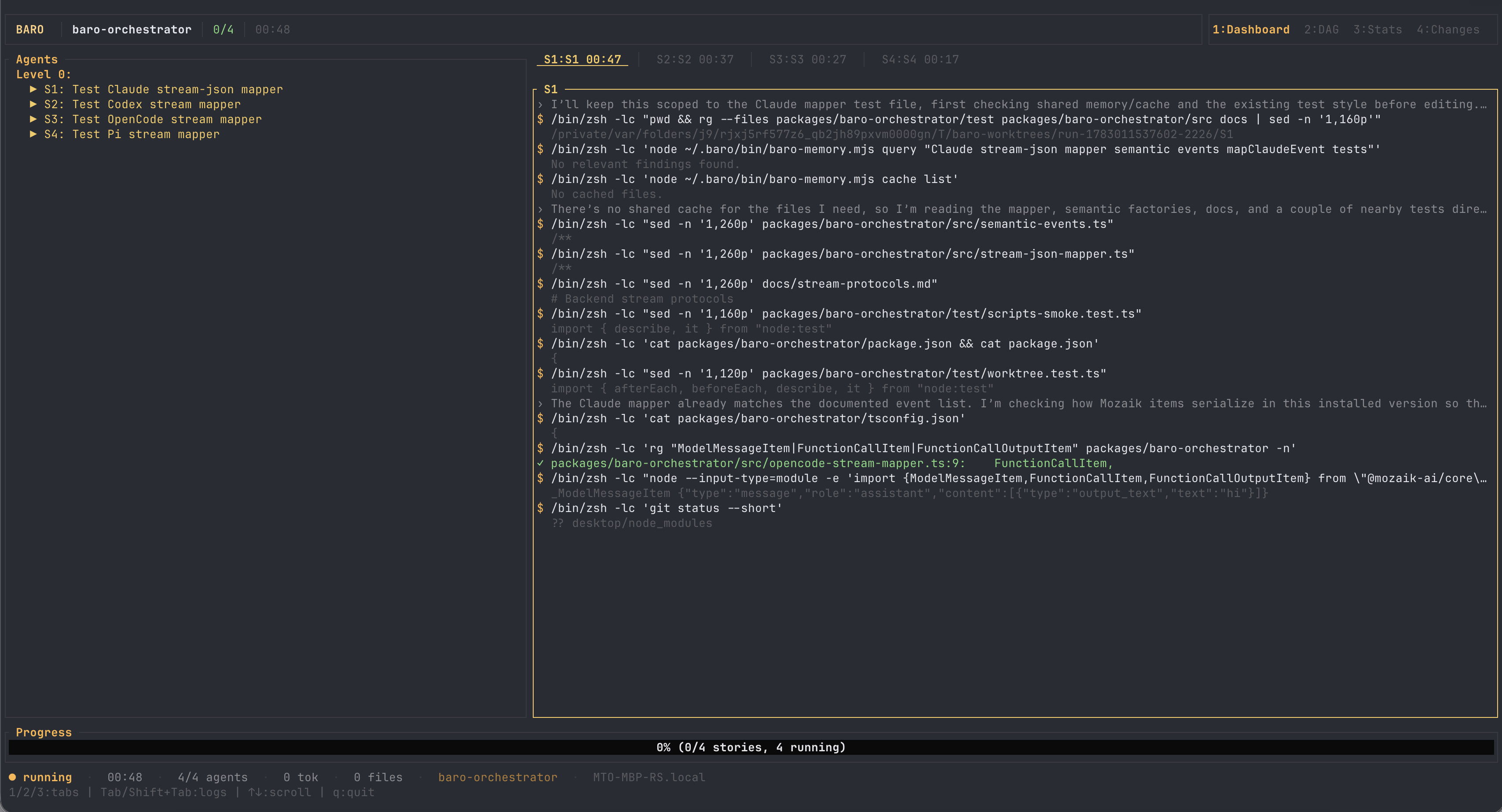
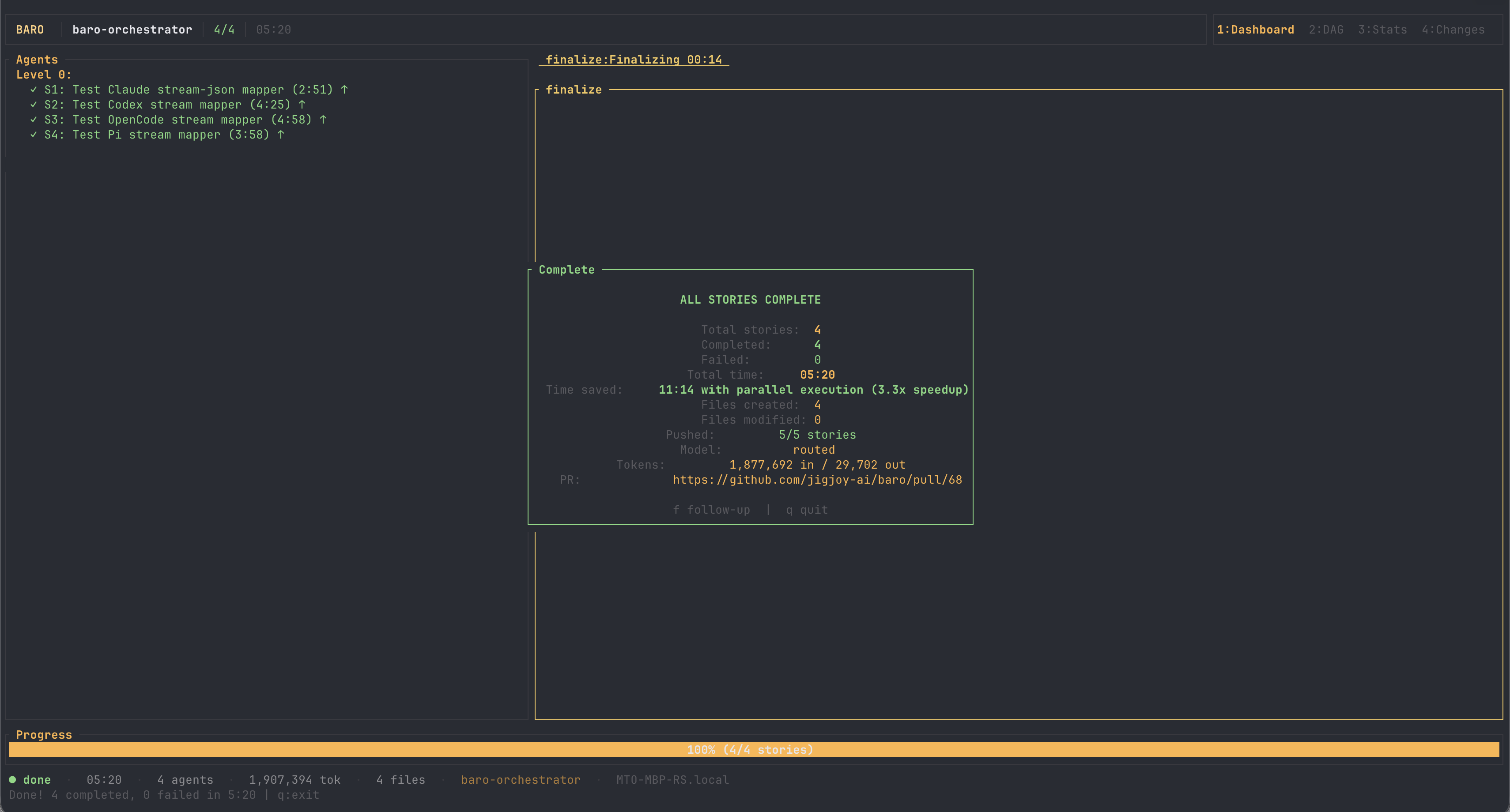
Five minutes twenty seconds of wall clock for what would have been sixteen and a half minutes sequentially — the agents' own summed working time. Four agents, four worktrees, zero merge conflicts, because the independence was verified before anyone started typing. That PR is public too.
This is the trade, stated plainly: the parallel run consumed 1.88 million input tokens against the focused run's 373 thousand — every agent carries its own context. Parallelism buys wall-clock time; it does not save tokens. On a subscription backend like Codex that trade is nearly free; on metered APIs you should know you are making it. baro's job is to make the trade only where it pays — and to refuse it where it doesn't.
If your backlog has tasks shaped like run two — independent surfaces waiting for a fleet — that is exactly what baro exists for. It runs from your terminal on your own subscriptions, or from baro.rs with nothing to install.
One more confession
The first time I hit Enter on that focused picker, the run crashed. The release that shipped the mode feature also shipped a broken planner bundle: a refactor had dropped a single main() call at the bottom of a script, the type checker had no objection to a function nobody calls, and the bundler tree-shook the entire entrypoint out of the published artifact. Every check was green. The artifact did nothing.
We found it, fixed it, and added smoke tests that actually execute every shipped entrypoint, because "the code is correct" and "the thing we published works" are different claims and we now test the second one. I am telling you this for the same reason the focused-mode admission is in here: the whole point of this post is that the bugs were the teachers. It would be a strange lesson to publish dishonestly.
Where this lands
Execution modes shipped in baro 0.70.15 — CLI and cloud. Auto is the default: intake classifies, you confirm or override in the picker, headless and cloud runs surface the decided mode and its reason on the run itself. Focused runs collapse to one story by contract. Parallel runs have to name their independent write surfaces to earn the fan-out.
I still believe the parallel DAG is baro's reason to exist — run two is exactly the kind of task where one session grinds for twenty minutes and a fleet finishes in five. But I no longer believe every task should be shaped like my tasks. The tool that gets to be your daily driver is the one that knows the difference — one goal at a time, before the first agent spawns.
baro is open source at github.com/jigjoy-ai/baro — both runs from this post are open PRs there. The cloud version with the same mode selector lives at baro.rs.

Different is better than better.
Made with baro, on baro, about baro — including the bugs.
