Benchmarking Claude (via Claude Code) and GPT-5.5 (via Mozaik) in the same parallel-agent run.
Today I shipped a real change in baro. Until now it was Claude-only — every agent in the DAG shelled out to Claude Code. One flag — --llm openai — now swaps every model call in the run. Architect, Planner, Critic, Surgeon, Story Agents. Same Mozaik event bus underneath both. The only thing that moves is the provider.
I'd been carrying an assumption for months that I'd never tested: that Claude Opus 4.7 was the right brain for this. Now I had an excuse to find out.
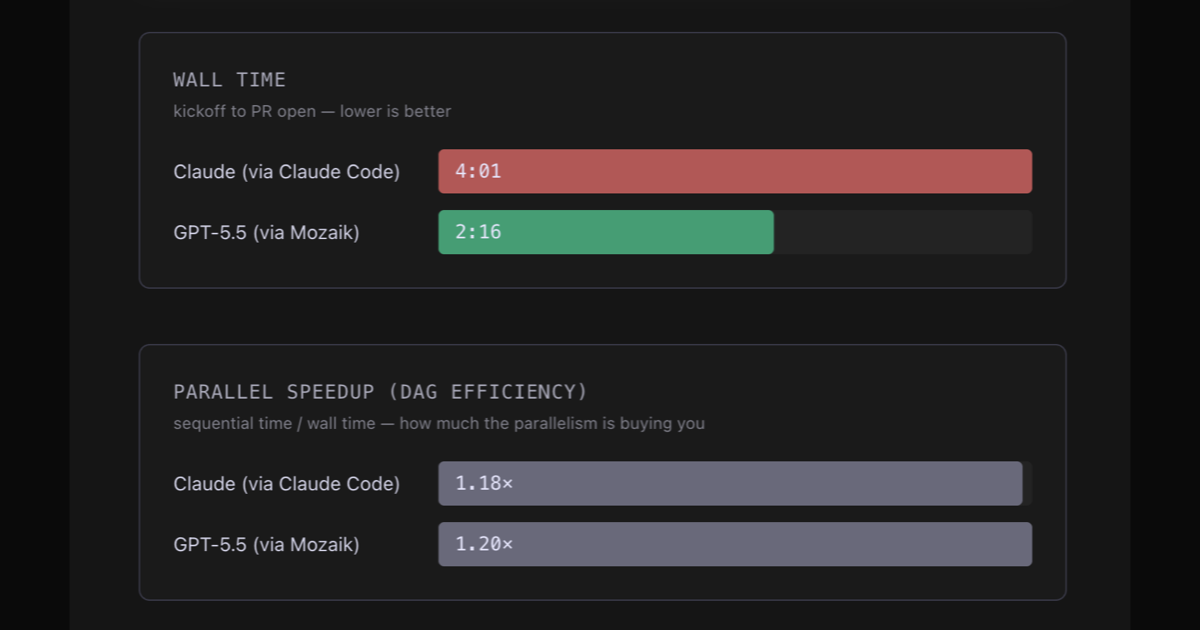
Same goal, same starting branch, same baro version. Claude on one clone, GPT-5.5 on the other. I expected Claude to win on code quality and lose on wall time by a hair.
It didn't. GPT finished in 2:16, Claude in 4:01 — almost 2× faster. And when I read the two PRs, the gap there went the same direction.
"Claude" and "GPT" don't mean what you think
Before the numbers — the most-misread part of this whole comparison. The two paths in baro aren't direct API calls to two providers.
--llm claude shells out to Claude Code in headless mode (claude -p). Auth comes from your Claude Max subscription. Every story baro runs eats the same quota as your interactive Claude Code sessions. Right now, a multi-hour parallel baro run costs you nothing on top of the $200/mo you already pay.
--llm openai is the opposite — a Mozaik-native call straight to the OpenAI Responses API, billed per-token against an OPENAI_API_KEY. No subprocess, no CLI in between, no subscription.
Same orchestration on top. Two completely different economic and latency profiles underneath. That's the real comparison.
The setup
I picked something I'd actually want shipped: add an Anthropic provider to Mozaik so the framework supports Claude alongside OpenAI. A runtime, three model classes (Opus 4.7, Sonnet 4.6, Haiku 4.5), a reasoning-effort helper, public exports, the package.json wiring. Real symbols, real type contracts. Not a toy.
Two sibling clones of the Mozaik repo, both reset to the same commit on main. Identical GOAL.md in both. baro 0.38 on both. Then:
baro --llm claude "$(cat GOAL.md)" # clone A — every phase via claude -p
baro --llm openai "$(cat GOAL.md)" # clone B — every phase via OpenAI ResponsesCritic stays on gpt-5.4-mini on the OpenAI side — it's the highest-volume call in a run and the verdict is a structured pass/fail. Flagship reasoning doesn't move that needle.
The numbers
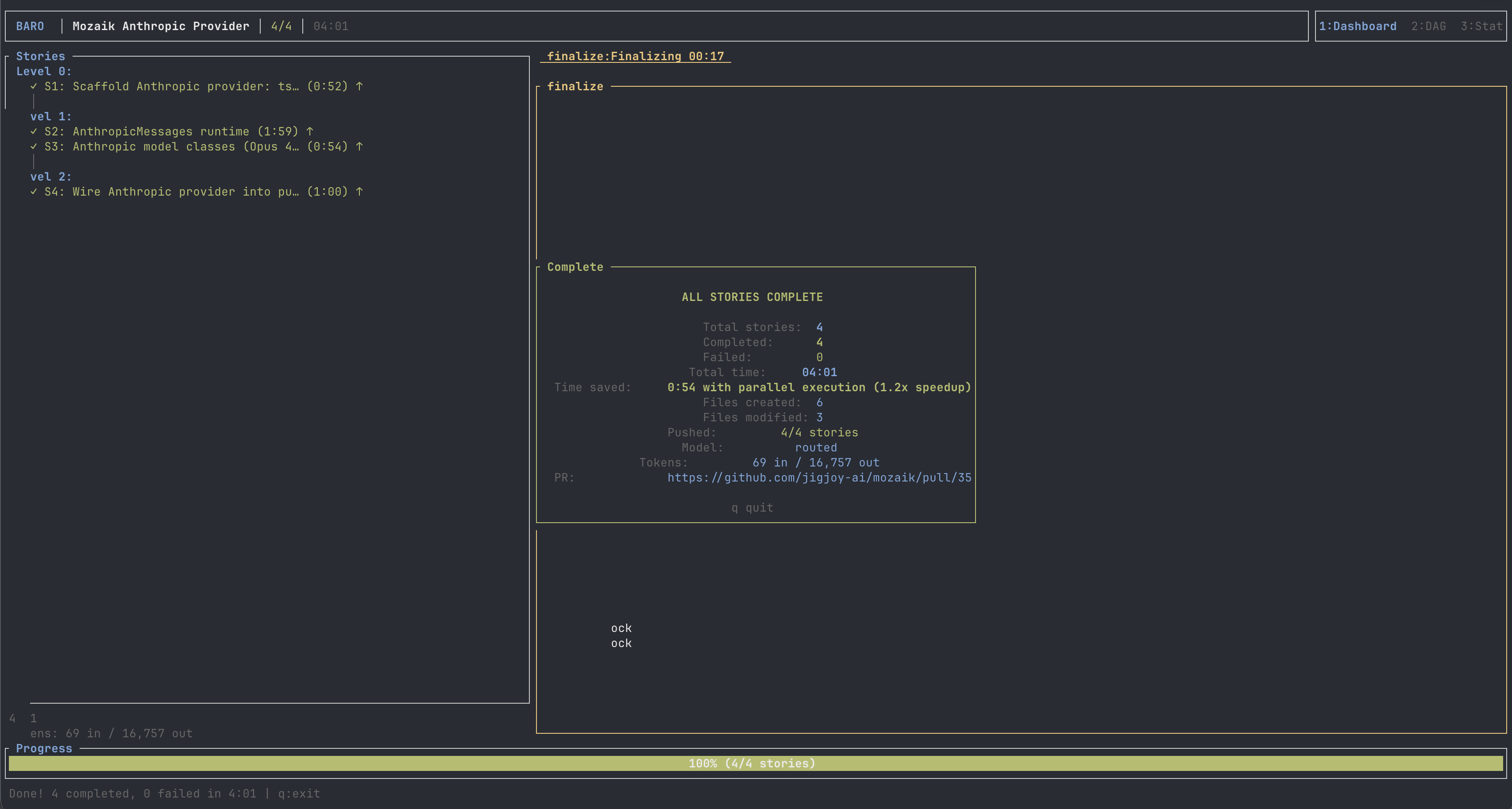
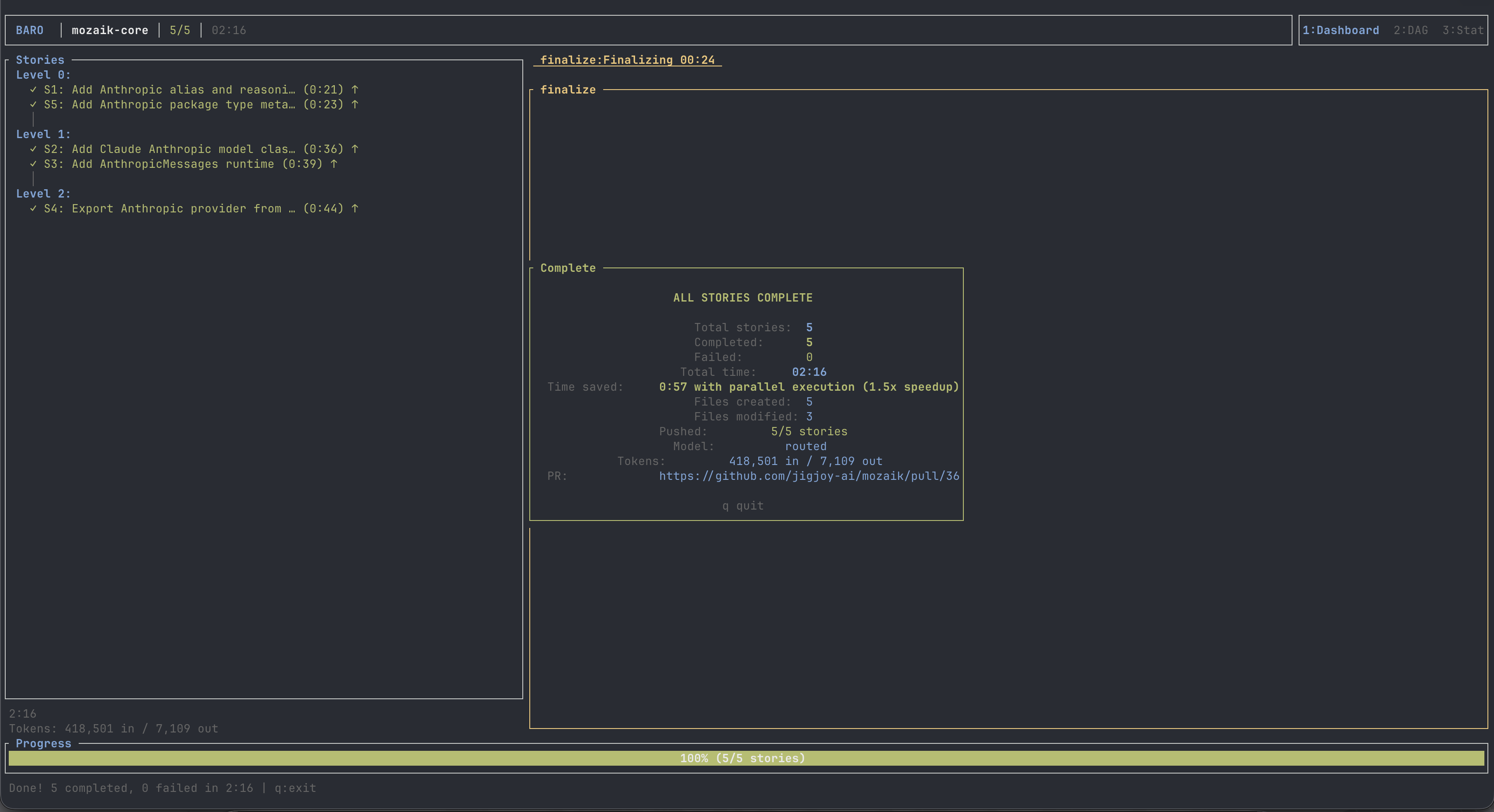
Look at the parallel-speedup row before the wall-time one. 1.18× vs 1.20×. A wash. Both runs built the same DAG — a foundation story, two parallel stories that import from it, a wire-up at the end — and both got the same parallelism out of it.
So the 1.78× wall-clock gap isn't about DAG quality. It's about how long each per-story request takes to come back. And on the Claude side, that number stacks two things: Opus 4.7's response time, plus Claude Code's subprocess overhead. GPT was going straight to the API. Some of the gap is the model. Some of it is the layer in between.
Reading the two PRs
This is where I expected the script to flip. I've been hand-tuning baro's prompts for Claude for months. GPT-5.5 was seeing all of them cold.
Most of the surface area tied. PR #35 (Claude) and PR #36 (GPT) landed in the same directories, used the same tsconfig alias, both produced the right AnthropicMessages runtime shape. Both kept let request: any instead of reaching for the typed SDK helper. Both missed the same goal line — neither implemented the explicitly-requested AnthropicInferenceRunner. Both undersized maxOutputTokens on Opus (real cap is 64k; Claude wrote 32k, GPT wrote 8k).
Where they diverged was the runtime mapping. Three things mattered:
- Same-role message coalescing. Anthropic's Messages API wants consecutive same-role items merged into one message with multiple content blocks. GPT's PR has a helper that does this. Claude's pushes each item as its own message, which quietly breaks the moment a real agent loop emits two tool uses in a row.
- Reasoning-block mapping. When Anthropic returns a
thinkingblock, the readable text lives inblock.thinking. Claude's PR mapped that text intoencryptedContentand left the actual content undefined. Any downstream code that reads the reasoning text gets nothing. GPT got it right. - Tool-call argument parsing. Both parse
item.argswithJSON.parse. GPT wraps it in a try/catch. Claude doesn't, so any malformed JSON the model emits crashes the loop.
Claude won exactly one round on hygiene: it created the src/providers/anthropic/index.ts barrel that backs the new typesVersions entry. GPT forgot the barrel — its package.json claims a subpath that won't exist in the built dist/. A one-line fix, but a real bug.
On the things I cared about — the runtime correctness, the defensive parsing, the API-spec adherence — GPT's PR was the better starting point. It got faster and more careful on the same goal. That's not the trade I would have predicted.
Caveats before anyone screenshots a bar chart
One task. Adding a provider to a framework that already has a sibling provider is a mirroring exercise. The agent gets to study the OpenAI code right next to it and translate. That plays to GPT's strengths more than to deep reasoning. Other tasks might tilt the other way. I haven't run them yet.
The 1.78× isn't pure model-vs-model. GPT-5.5 was going through Mozaik straight to the API. Claude Opus was going through Claude Code, which adds its own subprocess overhead on top of model latency. I don't know the split from this run. The "what's next" section below has the fix.
The durable finding isn't "GPT is faster than Claude." It's that per-story latency dominated DAG efficiency. The parallel speedups were identical; the whole gap came from how long each request took. If you're optimising a multi-agent system for wall clock, the work to do is "make each call faster" or "make fewer calls," not "parallelise harder." Different levers. I'd been pulling the wrong one.
Which one to pick today
The two paths aren't just "Claude vs GPT." They're "subscription vs API." That's the actual decision.
--llm claudeif you want to amortise your Claude Max subscription. Run baro for hours; pay $200/mo total. The slower wall time is the price.--llm openaiif you want raw wall-clock speed. Roughly $1–2 per run like this with cache hits, and you get the PR back in roughly half the time.
Worth flagging: the subscription-sharing trick has a short shelf life. Anthropic announced that on June 15, claude -p stops billing against Claude Max and starts requiring its own API key. After that the cost case for the Claude Code path collapses — it just becomes "Anthropic API calls with extra subprocess overhead." Until then, the Claude path is essentially free for anyone with Max.
What's next
Claude Code in the middle is the honest gap in this comparison. The right next step is to take it out.
I'm adding a third mode: a Mozaik-native Anthropic runtime — the same shape as the OpenAI Responses runner, talking to @anthropic-ai/sdk directly with an ANTHROPIC_API_KEY. The ironic part is that this runtime is roughly what the two PRs above were trying to add to Mozaik itself. Once it's in, I'll run the same goal a third time — Claude Opus 4.7 going through the same native path GPT-5.5 used here. That run will isolate model from transport, and that's the only honest version of this comparison.
I expect the gap to close. By how much is the question this post can't answer yet.
The thing I keep coming back to: baro's job is to be a good runtime regardless of which brain you put behind it. Watching the same DAG get the same parallel speedup under two completely different providers is the most reassuring data I've collected about the design. The model is replaceable. The orchestration is what I built — and it ran the same way on both.
Try it, read it
baro 0.38 is on npm and GitHub. Both PRs from the benchmark are public — #35 (Claude) and #36 (GPT). Read the actual diffs, not the summaries — that's where the interesting parts are.
If you want to run your own: clone any repo twice, drop the same goal in both, run baro with --llm claude and --llm openai. Reset hard between attempts. The findings show up in the places where the two agents disagreed about what the goal even meant.

Different is better than better.
Made with baro itself. 🤖
