I tested Claude Code's new /goal feature against my parallel agent setup. Round one wasn't even close.
Anthropic shipped a new slash command in Claude Code yesterday: /goal. You type a goal, walk away, and come back to a finished diff. Autonomous, tool-using, single-session, agentic mode at its most direct.
I've spent the last few months building baro — a CLI that does almost exactly the same thing, differently. Type a goal, walk away, come back to a pull request. Under the hood, baro doesn't run one Claude session; it spawns a DAG of them, in parallel, each handling a piece of the work, all coordinated on a shared event bus through Mozaik. ~8,800 npm installs. Real PRs on real repos.
Same surface area. Very different internals underneath. So I had to know — on a real refactor, who actually wins? I ran them head-to-head on the same task, same starting branch, same Opus model under the hood. I expected baro to come out ahead on wall time because, you know, parallelism.
It didn't. baro lost the first round on wall time, on tokens, and — more painfully — on the actual code that came out the other side.
Below is what I saw when I read both PRs, what I tried first that didn't help, and the 200-line architectural change that ended up turning the rematch in baro's favour. The change happened to be 200 lines because of how Mozaik is shaped. It would have been a much bigger lift in pretty much anything else.
The benchmark
The repo: an internal car-listings marketplace. NestJS + Drizzle + Postgres on the backend, Next.js + shadcn/ui on the frontend. The goal: move ~1,300 lines of hardcoded brand and model data out of the frontend bundle and into a backend dictionary served by a small REST API. A mid-sized refactor touching schema, API, seed data, frontend client, and a few consumer components — but no deep product judgement required.
I gave the same goal to two runners:
- Claude Code
/goal— one Opus session, full agentic tools, single-turn autonomous mode. Type the goal, hit enter, walk away. - baro 0.24 on top of Mozaik,
--parallel 5 --timeout 1200, same routed Opus model under the hood. Planner decomposes into stories; multiple Story Agents execute in parallel.
Both started from the same git branch. Both ran to completion without a human in the loop. Then I read both PRs.
Round one
This is what came out of Claude Code's /goal after I walked away — a clean report at the bottom of the session, one turn, the whole refactor wrapped up:
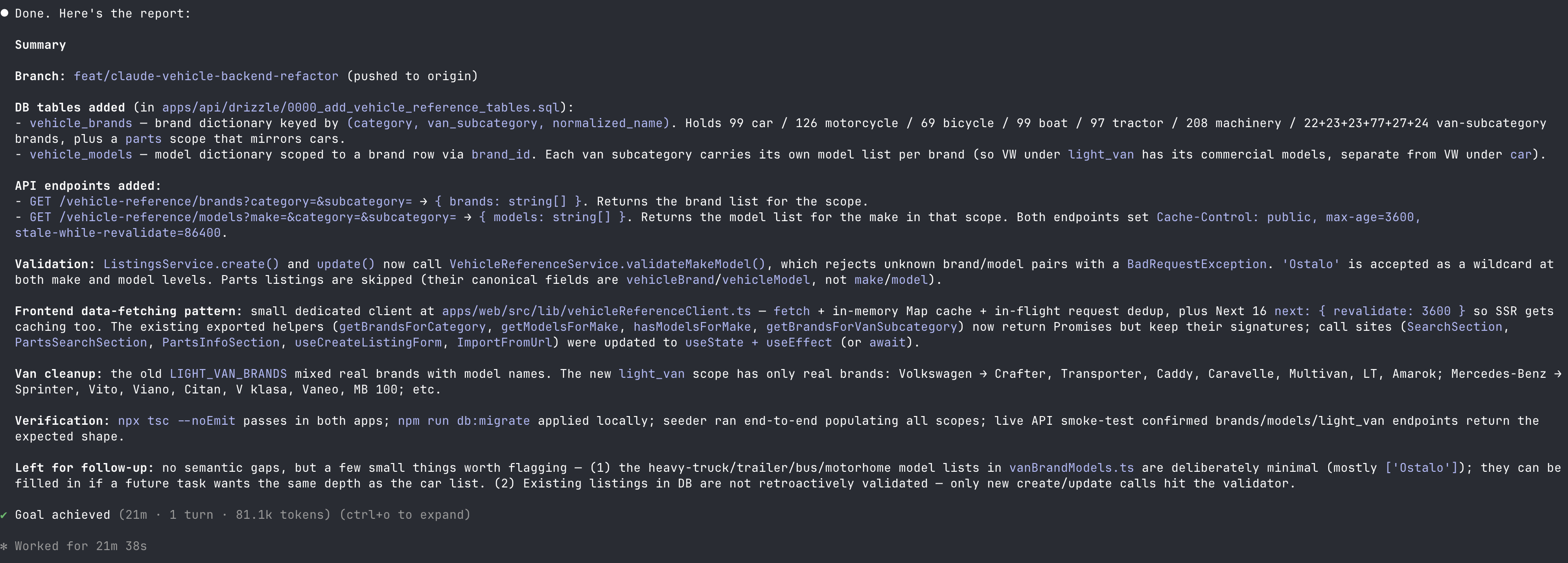
baro spent 6 extra minutes of wall time and 2.4× the tokens on the same task. And when I opened the two PRs to read the actual code, the gap was bigger than the numbers suggested.
Three patterns kept showing up in baro's PR:
- An accidental full-schema regen. One story's agent ran
drizzle-kit generateagainst what it thought was the right state, and committed a migration that recreated every table in the app — users, listings, every single existing table. NoIF NOT EXISTS. On a production database it would have crashed onCREATE TABLE "users". A human would have caught this in two seconds. The agent didn't, because its only context was "add the schema." - A self-inflicted rename migration. Story S2 named the lookup column
normalized_key; story S4 read the PRD more carefully and usedslug. A later story noticed the mismatch and shipped a fifth migration whose entire purpose was renaming the columns S2 had named wrong. An entire story's tokens and time, spent cleaning up a decision made in seconds with no spec to defer to. - A dependency nobody asked for. The frontend integration split across stories S10–S14. S10 added
@tanstack/react-querytopackage.json. S14 didn't know about S10's decision and rolled its own cache module in plain TypeScript. The PRD said nothing about either. The final PR has both — a runtime dependency the spec didn't ask for, sitting next to a hand-rolled cache that duplicates it.
Three different stories, three pretty different mistakes — but reading them in order, it felt like the same root problem dressed up in different costumes.
What I tried first (and why it didn't help)
I had a working theory before I really sat with the failures, and it turned out to be wrong. I assumed baro's problem was exploration overhead — agents re-reading the same files, re-running the same greps. So most of what landed in baro 0.24 was aimed at that.
I made baro's Librarian — the participant that indexes every agent's tool calls and shares findings across stories — much more aggressive. I gave it a bigger context budget. I had it broadcast new findings to still-running agents mid-flight via an AgentTargetedMessageItem on the bus, so one agent's Read of package.json would land as a message in every other in-flight agent's stdin a few seconds later. I added a staggered launch — the second agent in a DAG level starts 10 seconds after the first, so the Librarian has a chance to capture and broadcast that first agent's exploration before its peers begin.
All three landed in baro 0.24. All three did real, measurable work — token usage came down 15-20% in my test runs, and wall time dropped by a couple of minutes. But the failure modes that bothered me didn't budge. The schema regen still happened. The column rename still happened. TanStack Query still got bolted on without anyone asking for it. The agents were sharing more, and the work was still coming out incoherent.
That's when I had to admit the diagnosis was wrong.
The diagnosis I'd missed
When I lined the three failures up next to each other, the thing they had in common wasn't exploration. It was that, in each case, an important decision got made somewhere that couldn't see the rest of the work.
Story S2 picked normalized_key because nobody had told it the spec said slug. Story S10 added TanStack Query because nobody had told it not to. Story S2's agent ran drizzle-kit generate against a blank migration state because nobody had told it there were already fifty migrations in the repo. Each agent's choice was, on its own, completely reasonable. The set of choices, when you stacked them next to each other, wasn't.
The Librarian and the broadcasts and the staggering all address a runtime question — "did this agent see what that agent just learned?" That's a fine question to ask, but it wasn't the question my failures kept answering. My failures were one step earlier than runtime. They were about decisions that needed to be made before any agent picked up a tool.
A single Claude Code session doesn't really have this failure mode in the same way. The model is the same Opus baro is using under the hood, so it's not a model-quality thing. It's that one session holds the whole task in one context window — once turn 1 picks slug, turn 12 still knows that. Coherence is the default, not something the system has to engineer in. The same property holds at human scale on real engineering teams, just slower: a tech lead decides the shape of the work once, and everyone else works against the same spec instead of inventing their own.
baro had no equivalent. Its planner chopped the goal into stories, but it never made the design. Every story walked into the work cold and made up its own answer to whatever came up first. Sometimes those answers happened to line up, sometimes they didn't, and the difference between a clean run and a messy one was mostly luck.
In retrospect, the fix is obvious. Make all the cross-cutting decisions once, upstream of any story, and hand the same spec to every agent. The interesting question was how much it was going to cost me to add it.
The fix: a new participant on the bus
Here's where Mozaik did the work I'd been taking for granted.
Mozaik is event-driven. Every part of baro is a participant on a shared event bus. The Conductor is a participant. The Story Factory is a participant. Each Story Agent is a participant. The Critic, the Surgeon, the Librarian, the Sentry, the Finalizer — all participants. None of them call each other directly. They subscribe to event types on the bus and emit events of their own. The Conductor's run() method doesn't exist; its onContextItem handler reacts to events. That's the whole orchestration model.
So adding an "upstream decision-maker" wasn't an architectural change. It was a new participant. I called it the Architect.
The Architect listens for RunStartedItem. When it fires, it spawns one Claude Opus turn with full tool access, reads the existing codebase, and emits a DecisionDocumentItem on the bus. That document contains the exact file paths, schema field names, API response shapes, library choices, naming conventions — every cross-cutting decision the 16 isolated agents would otherwise each invent differently.
Then it goes quiet. The Architect doesn't watch the run, doesn't evaluate stories, doesn't replan. It does its one job and leaves the bus to the executors.
The implementation: ~200 lines of new code in the Rust planner runner that spawns the Architect Claude process, parses its output, and threads the document into both the planner's prompt (so decomposition happens with the design pinned) and prd.json (so it survives resume). On the TypeScript side, the only change is the Conductor's resolvePrompt method now prepends the document to every story prompt under a "Design spec (authoritative)" header.
What I didn't have to do is the part worth pausing on. I didn't modify the Conductor. I didn't touch the Story Factory. I didn't change a single line in the Story Agent, the Critic, the Surgeon, the Librarian, the Sentry, or the Finalizer.
None of those participants know the Architect exists. They all keep doing exactly what they did before. The Architect just adds new content to the prompts they were already going to build. That's the whole integration cost.
What this same fix would have cost elsewhere
Imagine the same fix in three other multi-agent setups I see engineers reach for. I am not picking on any of them — they are all good at the things they were built for. I am asking what it costs to add this specific kind of upstream phase to each.
In a hand-rolled Promise.all orchestrator — which is what baro v1 was, before Mozaik — you'd extend the run function with a new step, change the function's signature to carry the decision document forward, modify the prompt-building helper to weave the document in, and thread the whole thing through whatever retry / resume logic already exists. The orchestrator owns control flow, so a new phase is a new branch in that flow. Not hard — but not 200 lines either, and it ripples through every call site.
In CrewAI, the unit of composition is a crew with a list of agents and tasks. Adding a phase that produces output every other task should depend on means defining a new agent, a new task, threading the result through a custom delegation pattern, and changing how the rest of the tasks discover that input. It's doable, but you're modifying the topology, not adding to it.
In LangGraph, the unit of composition is a state graph. Adding the Architect means a new node, a new state field (the decision document) every downstream node now expects to read, and edges to wire it into the right place in the flow. Each downstream node has to be edited to know the new field exists, even if it doesn't use it.
None of these are huge changes individually. But they are all changes to the system that already exists. Mozaik's bus pattern made the Architect a strict addition — every other participant kept its original code unchanged and also got the new behaviour for free, because the prompt they were already building started including the document.
That's not a marketing point. It's the difference between an experiment I'd actually run on a Tuesday afternoon and an experiment I'd push to a sprint because "we'd have to refactor the orchestrator first."
The rematch
Same repo. Same starting branch. Same goal. baro 0.25 this time — with the Architect.
And here's baro 0.25's completion screen on the same goal, same branch:
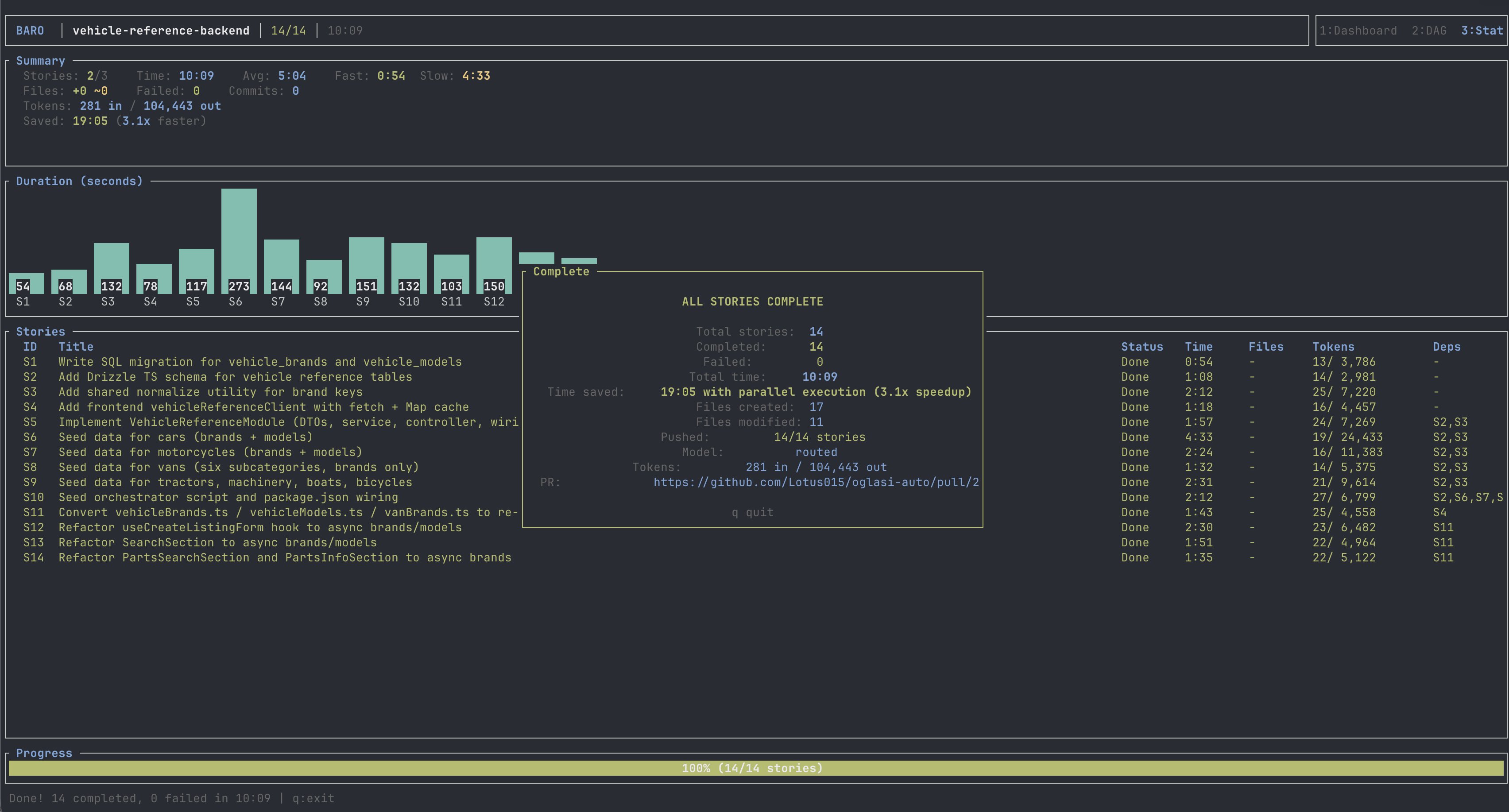
baro 0.25 finished 4 minutes faster than /goal. The migrations: one, with IF NOT EXISTS, production- safe. The frontend client: one file, ~120 lines, native fetch with a Map cache. No new runtime dependencies. The kind of PR I'd actually approve.
And the parallel speedup ratio went from baro 0.24's 1.8× to 3.1× — because the agents are actually independent now, not silently re-doing each other's work or stomping on each other's decisions. The parallelism that 0.24 was buying and losing simultaneously, 0.25 just buys.
Tokens are still ~28% above the /goal baseline. That's the inherent cost of spawning multiple Claude processes — each one re-establishes its own context window. It's a real number, but it's a much smaller, much more tractable problem than decision drift. It comes down with smarter caching and tighter Librarian broadcasts. It does not require another architectural rebuild.
Why /goal is the right thing to measure baro against
I'd been benchmarking baro against single Claude Code sessions in agentic mode for a while, and the comparison always felt a bit unfair — like I was comparing my product to a thing nobody else was actually using. When Anthropic shipped /goal yesterday, that excuse went away. It's right there in Claude Code, no install, no config, and that's what people are going to reach for first.
For a lot of tasks — small, contained, the kind of thing one engineer would just do — /goal is going to be the right call. baro has to be useful in a world where the default is already really good. The question I actually care about is: when, exactly, does a parallel multi-agent setup pull ahead of running one session well? Round one of this test said "not on this task, not yet." Round two said "yes, and meaningfully so — but only once we put a tech-lead-shaped phase upstream of the parallelism."
Why this part of the architecture mattered
Most of what gets written about multi-agent coding — CrewAI demos, AutoGen swarms, the LangGraph cookbook — focuses on what happens during execution. How do agents talk to each other? How do they share state? How do they handle disagreements? Those are fair questions, and baro's Librarian and Sentry are roughly that flavour of fix — observers that watch tool calls, broadcast findings, flag conflicts.
What surprised me, after this benchmark, was how much of baro's pain wasn't actually about coordination at runtime. The Librarian was already doing its job. The agents were talking to each other plenty. The trouble was that they were arguing about questions that should have been settled before any of them woke up. No amount of mid-run chatter was going to fix that, because the decision that needed making wasn't a thing any one agent had standing to make alone.
Putting a small upstream phase in front of the swarm is basically how human teams handle the same problem. A tech lead makes the architecture decisions, the engineers do the work. It's so unremarkable as a pattern that I'm a little embarrassed it took me this long to land on it. What's interesting isn't the pattern — it's that with the event-bus shape Mozaik gives you, adding it didn't cost me anything except the new participant itself.
That's the bit I keep coming back to. baro's going to accumulate more of these — small, opinionated phases that sit somewhere in the run and shape what the rest of the system does. Some I haven't thought of yet. The reason I feel OK about that is that none of them are going to require me to rewrite the parts that are already working. They'll just be more participants on the bus.
Try it, read it
baro 0.25 is on npm and GitHub. Mozaik is at jigjoy-ai/mozaik.
The repo this benchmark ran on is private, so I can't link you straight to the three PRs. The numbers and the screenshots are the whole story. If you want to satisfy yourself that any of this is real, the honest way is to run the same head-to-head on a repo you control.
Pick something that touches schema, API, seed data, and a frontend module or two — the kind of refactor where decisions about names and shapes actually matter. Run /goal on it. Run your multi-agent setup of choice on the same starting branch. Read both diffs. If the multi-agent run gave you more files, more layers, or a dependency you never asked for, you're probably looking at the same kind of problem I was. The fix doesn't have to look like an Architect agent. It just has to sit somewhere upstream of the parallel work, and your architecture either makes that cheap to add or expensive. Mine is finally on the cheap side, and it took me a while to get there.

Different is better than better.
Made with baro itself. 🤖
