I tested Claude Code vs OpenAI Codex in my parallel agent setup. Then I built a hybrid.
On June 15, Anthropic is turning off subscription billing for claude -p. The same headless CLI mode that baro depends on. The same one Claude Code users have been quietly draining a $100-a-month plan through for months. After June 15, that flag still works — but it bills against an API key, at API rates.
I've spent the last few months building baro on top of that exact arbitrage. Type a goal, walk away, come back to a pull request. Under the hood, baro spawns a DAG of claude -p sessions in parallel — each one a Story, all coordinated on the Mozaik event bus, all billed against my single Max plan. A normal run costs me… nothing, in dollar terms. That's the trick. That's also the trick that breaks in three weeks.
So I went looking for somewhere to land. OpenAI shipped codex exec --json earlier this year — the same idea, headless one-shot inference, this time billed against a $100/month ChatGPT Pro plan. Same subscription arbitrage, different vendor. I added it as a third backend in baro, ran three real tasks through both sides, and watched what actually happened.
This post is what I saw. Three benchmarks, two backends, then the hybrid I ended up shipping — Claude only where it earns it, Codex everywhere else.
The setup
Each task is a real change I would have made anyway, not a synthetic benchmark. I picked three because one would have been a coin flip and two wouldn't have shown the spread:
- Feature add. Implement a fast-forward seek animation in
kaleidoskop— the hex-grid replay viewer for Mozaik runs. Replaces a silent jump with a high-speed burst of skipped events so users see the time-skip. - Refactor. Split
BaroEventForwarderinto one handler per event kind. A 400-line god-class pulled apart into Claude/Codex/Surgeon/Sentry-shaped submodules. - Greenfield. Build a Pomelo landing page from scratch. Next.js 15, Tailwind v4, Stripe-style hero, pricing, features, footer. Same one-paragraph prompt to both sides.
Both backends ran on the same starting branch, with the same prd.json, the same per-story timeouts, the same Mozaik DAG, the same CLAUDE.md / AGENTS.md context. The only thing I changed between runs was --llm claude → --llm codex. Every run was uploaded to kaleidoskop so you can scrub through them yourself — the replay links are inline below each task.
Methodology nit I'll come back to later: Claude Code reads CLAUDE.md, Codex reads AGENTS.md. baro mirrors one into the other before each story so neither side has a context advantage. There's a section near the bottom on why I did this and what changed when I didn't.
Task #1 — Feature add: the seek-burst animation
Same prompt to both: "Replace kaleidoskop's silent seek with a high-speed burst of skipped events so the user sees the time-skip. Phase 2.5 spec is in the PRD." Real change, real PRD, real review on the other side.
Two things jump out of that chart. The first one's the punch line: Codex burned ~11× less of my subscription budget for an equivalent diff. 0.18% versus 2.0%. That's not noise. That's the entire economic case for adding a second backend at all.
The second one is the part that stuck with me. Codex made 3.6× as many tool calls to land equivalent work. Reads, greps, list-files, file-writes, then more reads to verify the writes. Same goal, same scaffold, 4× the tool surface area. I noticed this on Task #1 and assumed it was a one-off — different model, different training, fine. Then I saw it again on Task #2, and again on Task #3, and I had to take it seriously.
The diffs themselves were both fine. Claude shipped a tighter, slightly more idiomatic implementation. Codex split one of Claude's stories into two — animation logic separate from playback state mutation — which is arguably the better call architecturally. Neither side hallucinated, neither side broke the test suite. The Critic on both runs flagged the same one issue (missing easing curve config) and both Story agents fixed it. Functionally a tie. Economically not close.
Task #2 — Refactor: pulling apart BaroEventForwarder
BaroEventForwarder is the component in baro's orchestrator that translates Mozaik bus events into the JSON wire format the Rust TUI consumes. It had grown into a 400-line god-class with handlers for every event type all in one switch. The prompt: "Split this into one handler module per event kind, keep the public interface, add tests."
Ratio collapsed from 11× on Task #1 down to 2.8× on the refactor. Refactors are token-heavy on both sides because you're reading more than you're writing — and Claude's higher per-token cost meets Codex's higher tool-call count in the middle. The cheap-and- chatty axis matters less when the work itself is read-heavy.
Stylistically the diffs diverged in a way I didn't expect. Claude produced one handler file per event kind, plus a small dispatch table in the original location — minimal surface, minimal new types, clean. Codex produced one handler file per event kind, plus a shared HandlerContext dependency injection scaffold, plus a small registry, plus a base abstract class. Same goal. Three more layers of abstraction. Both worked. The Codex version is the one I'd expect a senior engineer to land if they were thinking about future event kinds. The Claude version is the one I'd write myself today.
Which one's right? I genuinely don't know. I left both PRs sitting in branches for an afternoon and came back; both still felt defensible. But I noticed the same pattern as Task #1 — Codex was reaching for tools (and for abstractions) more freely. Roughly 3.6× the tool-call rate per equivalent diff. That's twice in a row.
Task #3 — Greenfield: the Pomelo landing
The prompt was a single paragraph. "Build a marketing landing for Pomelo, a fictional CLI productivity tool. Next.js 15 App Router, Tailwind v4, React 19. Hero, three feature blocks, pricing, footer. Make it feel like a real product." No design system, no brand, no copy. The interesting thing is exactly what each model assumes when you don't tell it.
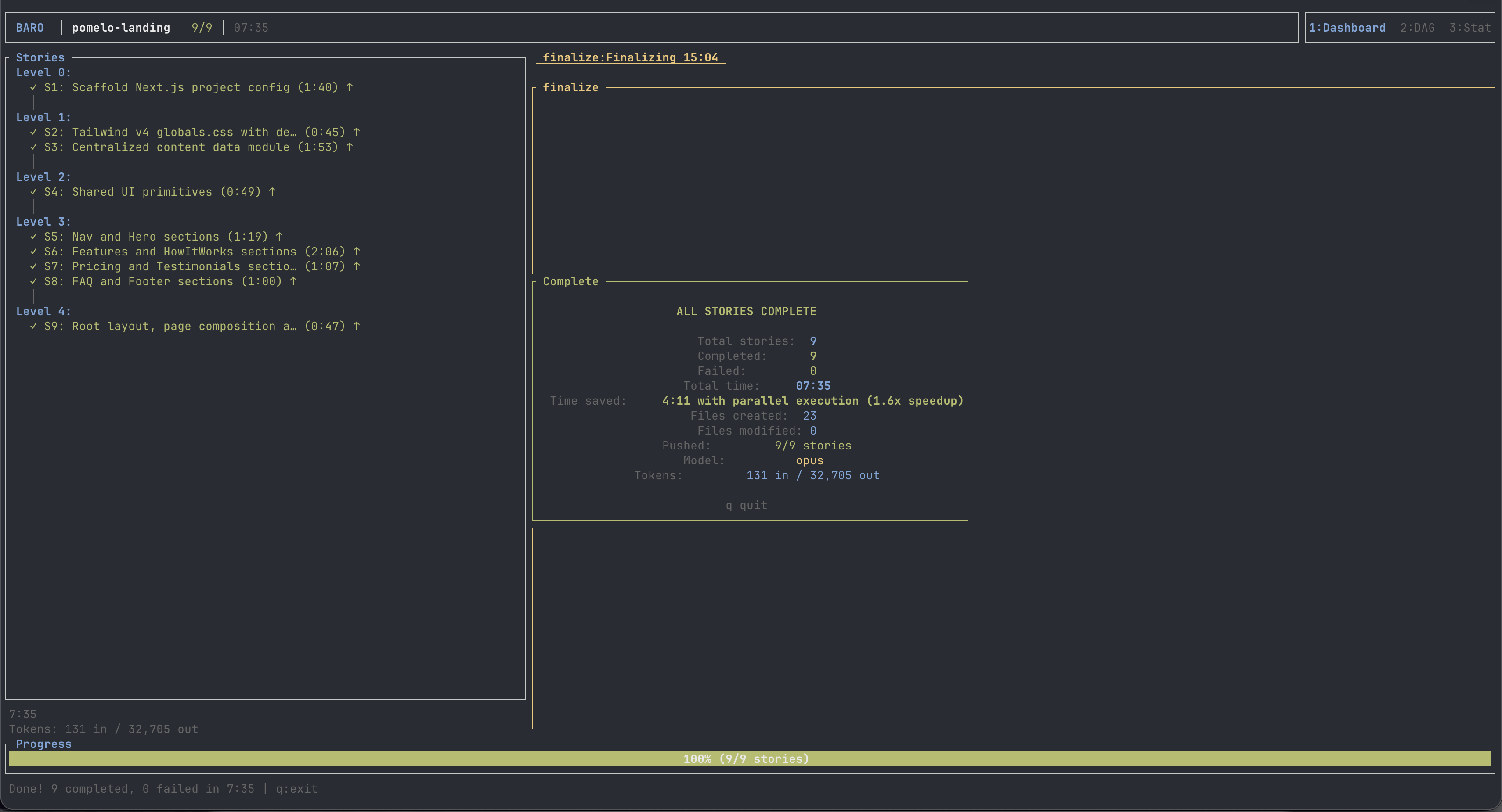
Ratio back up to ~5.8× on the greenfield — because greenfield is write-heavy, and write-heavy is exactly where Codex's per-token economics win. Claude reads less and writes less; Codex reads-greps-reads-writes-reads and bills a fraction per token. The bigger the green field, the wider the spread.
But the more interesting comparison was the actual landings.
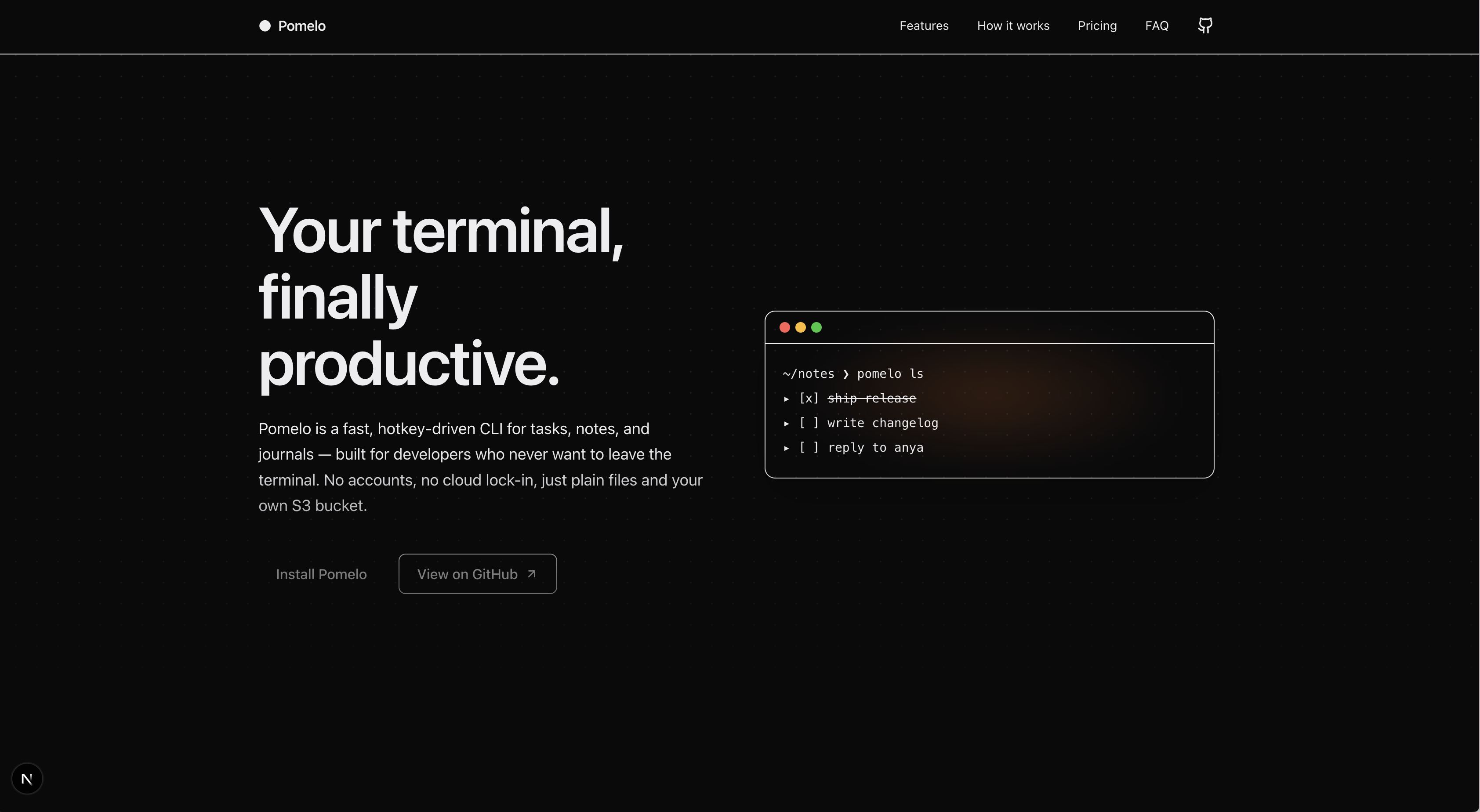
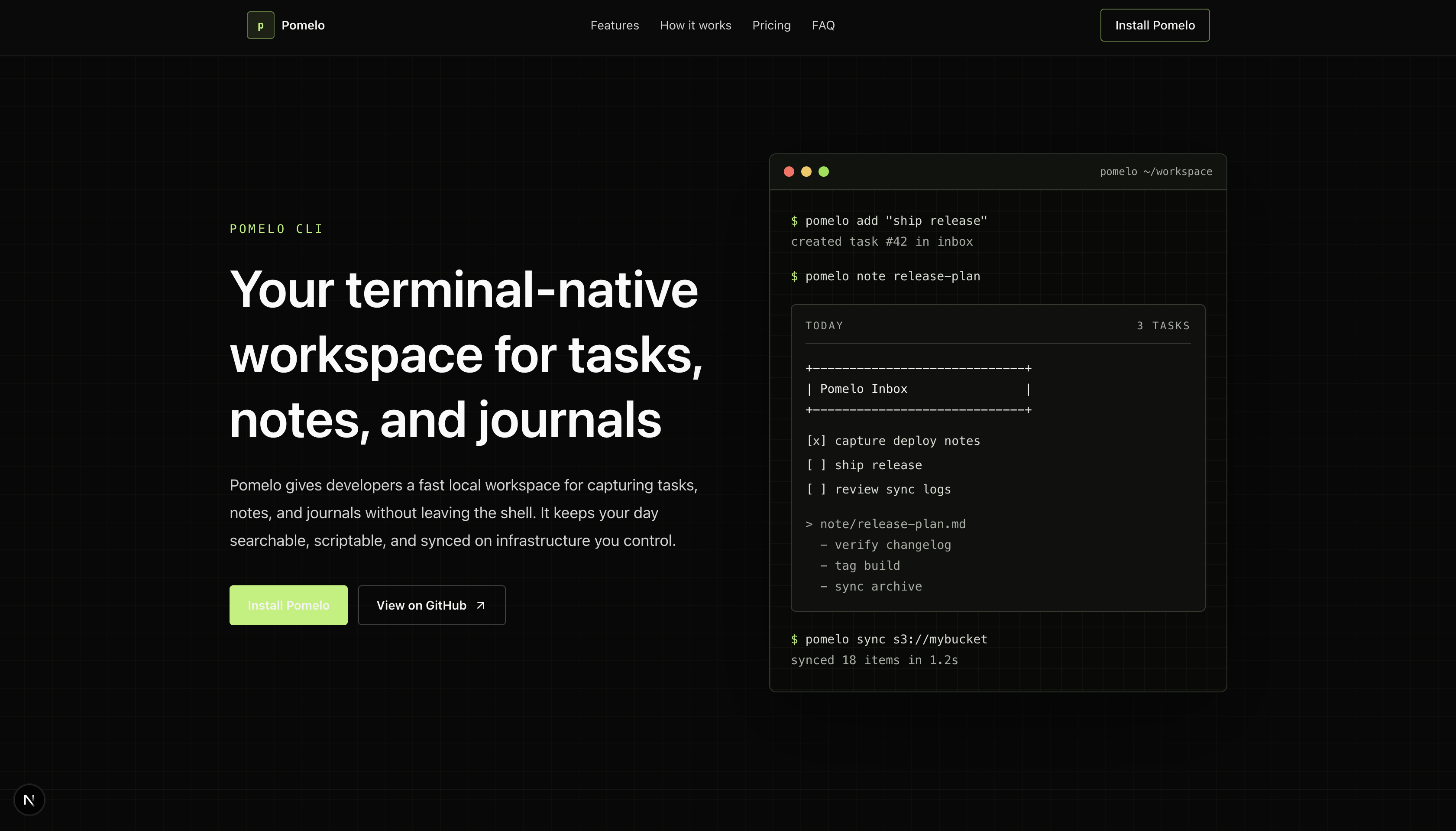
Two different idioms, neither broken. Codex went for what I can only describe as conversion-optimized SaaS landing page: visible terminal mock in the hero, install CTA in the top nav, scannable 3-column features, a green "MOST POPULAR" pill in pricing, a testimonials row, a brand color that's actually used rather than implied. Claude went for what looks like a Stripe / Linear graduate's thesis: oversized typography ("Your terminal, finally productive."), aggressive whitespace, no brand color louder than the type, a clean two-tier footer.
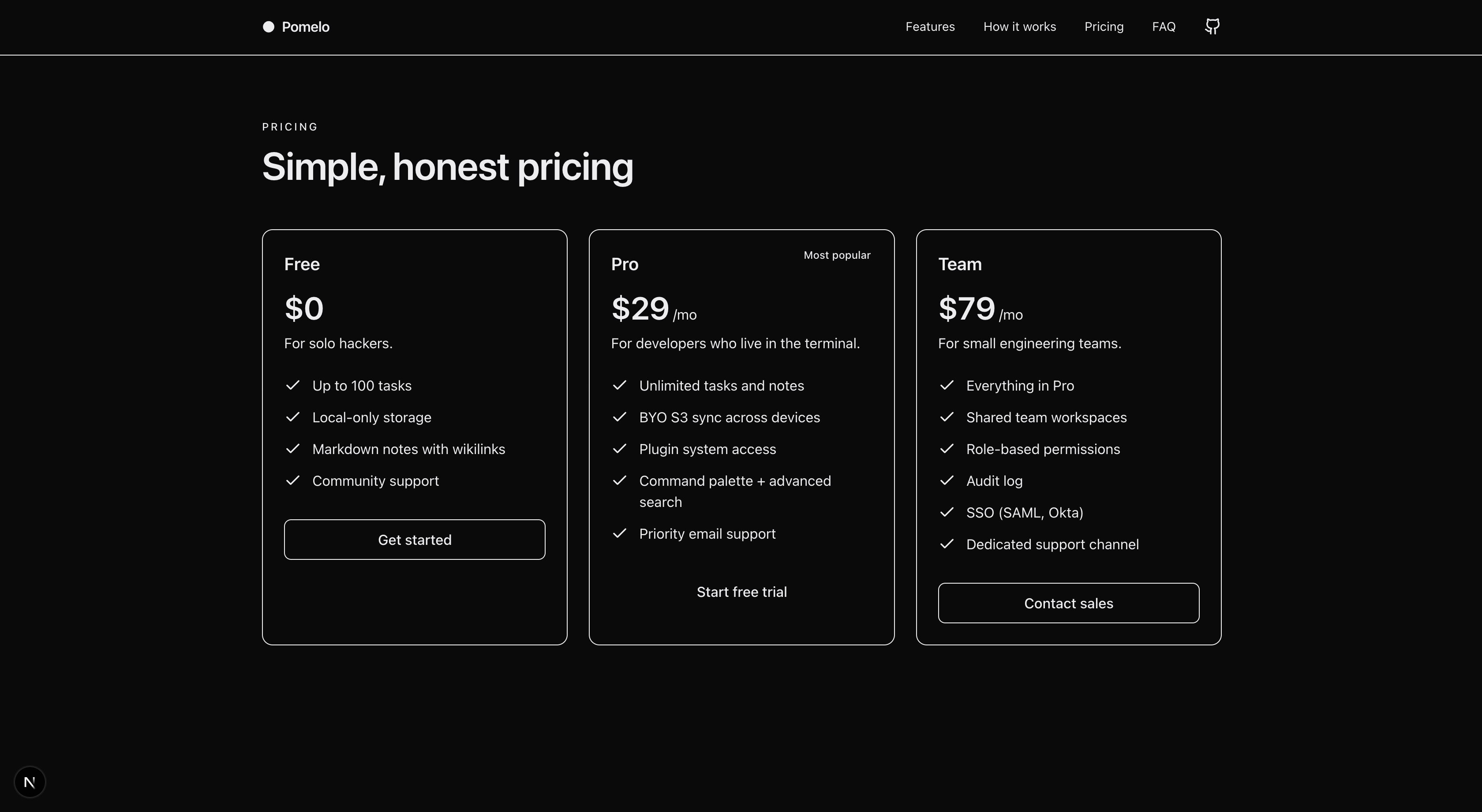
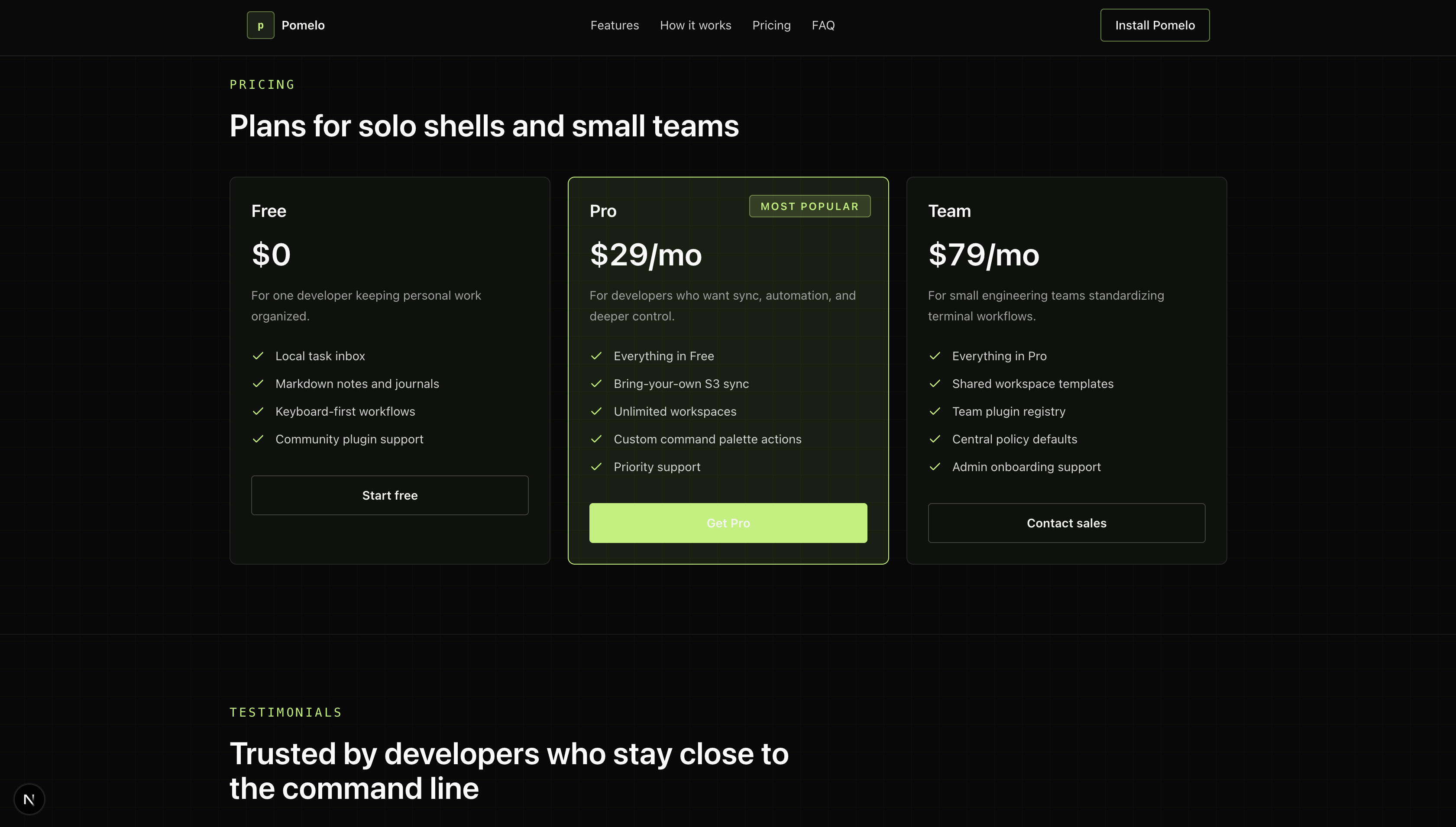
Honest read: I liked Codex's better. Personal preference. The terminal mock in the hero is a real "oh this is a CLI tool" signal that Claude's page never quite delivers. The pricing card with the green pill is harder to ignore than Claude's three identical columns. A colleague I showed both to immediately picked Claude — same reasons in reverse. "It's quieter. It scales."
But there's one objectively measurable difference, and Claude wins it: accessibility. The green "Get Started" button in Codex's hero is light green on medium-green, and the contrast ratio is somewhere between 3:1 and 4:1 by eye. WCAG AA needs 4.5:1 for text under 24px. Claude didn't make a single contrast mistake across the entire landing. I didn't ask either model to think about accessibility. One did anyway.
Subjective: two different design idioms, neither broken, personal preference splits cleanly. Objective: Claude was accessibility-rigorous without being told to be, Codex was not. If your audience is technical, that hero mock matters more. If your audience is regulated or visually impaired, that contrast ratio matters more. Neither model asked me who the audience was — both made assumption defaults that reflected their training.
And on the tool-call count: third time in a row, Codex used roughly 3.9× the tool calls. 248 vs 64. This is a real pattern now, not noise. Which means I have to ask the next obvious question.
Methodology check — is this just AGENTS.md missing?
Claude Code reads CLAUDE.md at the project root. Codex reads AGENTS.md. In baro's default setup I write CLAUDE.md at session start, but until v0.43.3 I wasn't mirroring it to AGENTS.md — so the Codex stories were running with no project context other than the PRD. Plausibly the 3.6×–3.9× tool-call ratio was just Codex rediscovering the codebase on each story.
I shipped the mirror in v0.43.3 and reran Task #2 as a v3 control. Two things to check: did the AGENTS.md actually get written this time (it had failed silently in v2 because CLAUDE.md was already present and the spawn step short- circuited), and did giving Codex the same context Claude had change anything material.
Difference is in the noise. Codex's tool-call appetite is not a missing-context artifact. It's a model behavior. Which is actually a relief — if it had been a setup gap I'd have had to publish a correction in a month. As it is, the 3–4× tool-call ratio is the model.
(The mechanical part of this experiment is worth a note. The v2 rerun looked like it had AGENTS.md present and showed no change. It hadn't. CLAUDE.md was already on disk from the previous run, the mirror step short-circuited, and the AGENTS.md file never actually got written. v0.43.3 makes the mirror idempotent at all three call sites and writes AGENTS.md from whichever copy is freshest. v3 was the genuine controlled comparison.)
The realization
Three tasks, two models, three different ratios. But there's a pattern under the noise.
- Story phase (the parallel agents that actually write code) — Codex is 3–11× cheaper depending on read/write ratio, and the diffs are competitive. This is where the spend lives. This is where Codex wins.
- Critic phase (acceptance evaluator) — Codex's higher tool-call appetite actually helps; it reads more of the diff before judging. Claude's Critic sometimes accepts diffs Codex would have flagged. Codex wins here too.
- Architect / Planner / Surgeon phases (the small upstream agents that decide what to build) — these are token-cheap (1–3% of total spend) but accuracy-critical. Codex's tendency to over-decompose and over-abstract actually hurts. Claude's tighter output is the right shape upstream.
The fix isn't to pick a backend. The fix is to route per phase. Claude where accuracy matters more than tokens. Codex where tokens matter more than tokens. (You read that right.)
Building the hybrid in baro 0.44.0
I extended --llm to accept hybrid as a preset, plus five per-phase override flags so you can mix anything yourself:
# the preset — Claude for the small upstream phases, Codex for the
# parallel story+critic work that dominates the budget
baro --llm hybrid "your goal here"
# equivalent to:
baro --architect-llm claude \
--planner-llm claude \
--story-llm codex \
--critic-llm codex \
--surgeon-llm claude \
"your goal here"Under the hood, OrchestrateConfig grew three optional fields (storyLlm, criticLlm, surgeonLlm) and each phase factory now branches on its own setting before falling back to the default. The Story DAG can have Codex Story participants running alongside Claude Story participants on the same bus — the Mozaik event schema doesn't care which model produced the event, only that the shape is identical. (This is the kind of thing that's free because Mozaik already had it.)
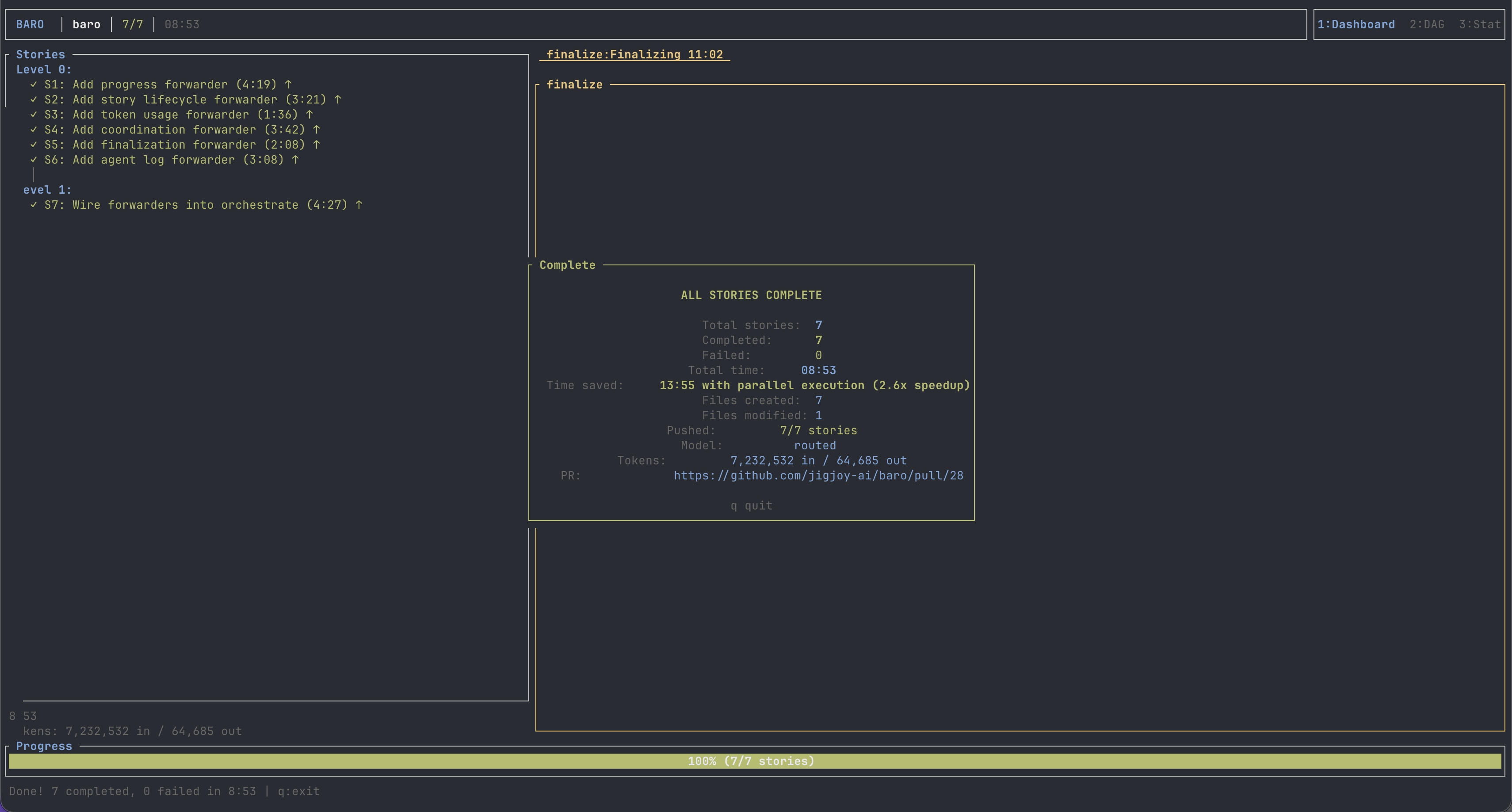
Hybrid benchmark — Task #2 rerun
I reran the BaroEventForwarder refactor — same prompt, same branch — under --llm hybrid and put the result alongside the two pure runs:
Read it carefully. Pure-Claude burned 14% of the Claude 5h cap on this single run. Pure-Codex burned 5% of the Codex 5h cap. Hybrid burned 3% on each side. The total subscription footprint of the hybrid run is roughly a third of the pure-Claude run — because the expensive parallel Story work moved to Codex, and the Claude side only paid for the small upstream phases.
The diff was indistinguishable from pure-Codex (Codex did the actual writing). The plan was tighter than pure-Codex (Claude did the architecture). Critic was clean on first pass. That's the version I shipped.
What happens after June 15
Here's the part I care about. On June 15, Anthropic stops billing claude -p against a subscription. Either you sign in with API keys (pay per token, retail), or you wait for them to bring back subscription-mode behind some other path. For baro, that's the difference between a $0 run on my Max plan and a paid run against my own API quota.
I costed Task #2 three ways at post-June-15 prices, using the same token counts from these runs:
The hybrid is roughly 12× cheaper than going pure-API on Claude, and it keeps the part of Claude that I actually value — the planning quality — without paying retail for the bulk write work. Pure-Codex is technically the cheapest but you lose the upstream tightness. For most runs the $5 gap is worth it. For some runs (small features, simple tasks) it isn't and you go pure-Codex.
That's the moat I was looking for. Not a single backend, not a single subscription — a router that knows which agent in the DAG is worth paying premium for.
Verdict — when to pick what
- Pure Claude — only if you need maximum diff tightness on a single-shot small change and the budget doesn't matter. Pre-June-15: still the default for small runs. Post-June-15: hard to justify.
- Pure Codex — small features, greenfield work, exploratory generation where ~4× tool calls are fine and you just want the diff. Anything where the cost gap dominates the architecture gap.
- Hybrid — anything serious. Refactors, multi-file changes, anything where the upstream plan matters as much as the downstream writes. This is baro's default starting in 0.44.0.
Try it
# install / upgrade
npm install -g baro-ai@latest
# you need both CLIs signed in:
# claude (Anthropic — Max plan or API key)
# codex (OpenAI — ChatGPT Pro plan or API key)
# default hybrid routing
baro --llm hybrid "add a fast-forward burst to kaleidoskop's seek"
# go pure on either side
baro --llm claude "small focused change"
baro --llm codex "greenfield landing page"
# mix it yourself
baro --architect-llm claude --story-llm codex --critic-llm claude \
"complex refactor where you want Claude reviewing"Every run uploads its audit log to kaleidoskop.jigjoy.ai if you opt in — same hex-grid replay viewer the run links above use. You can scrub through your own DAG, see which phase used which model, and look for your own opportunities to mix.
The whole point of this exercise was that I was looking for a vendor switch and ended up with a routing layer. The switch wouldn't have survived June 15. The routing layer will.
baro is on npm and GitHub. Mozaik (the bus underneath) is at jigjoy-ai/mozaik. kaleidoskop (the replay viewer) is at kaleidoskop.jigjoy.ai.

Different is better than better.
Made with baro itself — running --llm hybrid, naturally. 🤖
