I Stopped Babysitting AI Coding Agents. I Gave Them a Cloud and a Goal Instead.

For about a year my AI coding workflow looked like this: open a chat, give the agent a task, then sit there. Watch it think. Stop it when it wandered. Re-explain. Approve a diff. Wait. Approve another diff. Wait again.
It was faster than typing everything myself. But I wasn’t really delegating — I was pair-programming with something that needed me in the chair the whole time. One agent, one chat, one task, my full attention. The moment I tabbed away, progress stopped.
At some point the obvious question hit me: why is the unit of work “one agent I babysit” and not “a goal I hand off”?
That question is why I ended up building baro — and why my agents don’t run on my laptop anymore.
One agent in a chat is the wrong shape for real work
Real features aren’t one task. “Add JWT auth with role-based access control” is a dozen smaller things: the middleware, the token service, the guards, the migrations, the tests, the wiring. A single agent does them in sequence, in one context window, with you as the bottleneck approving each step.
But most of those pieces are independent. The token service doesn’t need to wait for the guards. If they’re independent, why are they running one after another, gated on me?
So I flipped it. Instead of one agent doing tasks in a line, baro:
- Plans the goal into a DAG — it breaks the feature into stories and figures out what depends on what.
- Runs a fleet of agents in parallel — independent stories execute at the same time, each in its own
git worktree, so they can’t step on each other’s files. - Has the agents review each other — a critic checks each story; a surgeon fixes what’s broken — before anything merges.
- Opens a build-verified pull request — with a stories table and stats. Not a diff for me to babysit. A PR for me to review.
I describe the goal. I come back to a PR. That’s the whole loop.
A real run
Here’s one I keep pointing people to, because the numbers are real and reproducible:
- One prompt describing a feature on a NestJS codebase.
- baro planned it into 33 stories.
- A fleet of agents built them in parallel — each branch isolated.
- It opened a PR with 808 passing tests.
- Wall-clock: ~71 minutes.
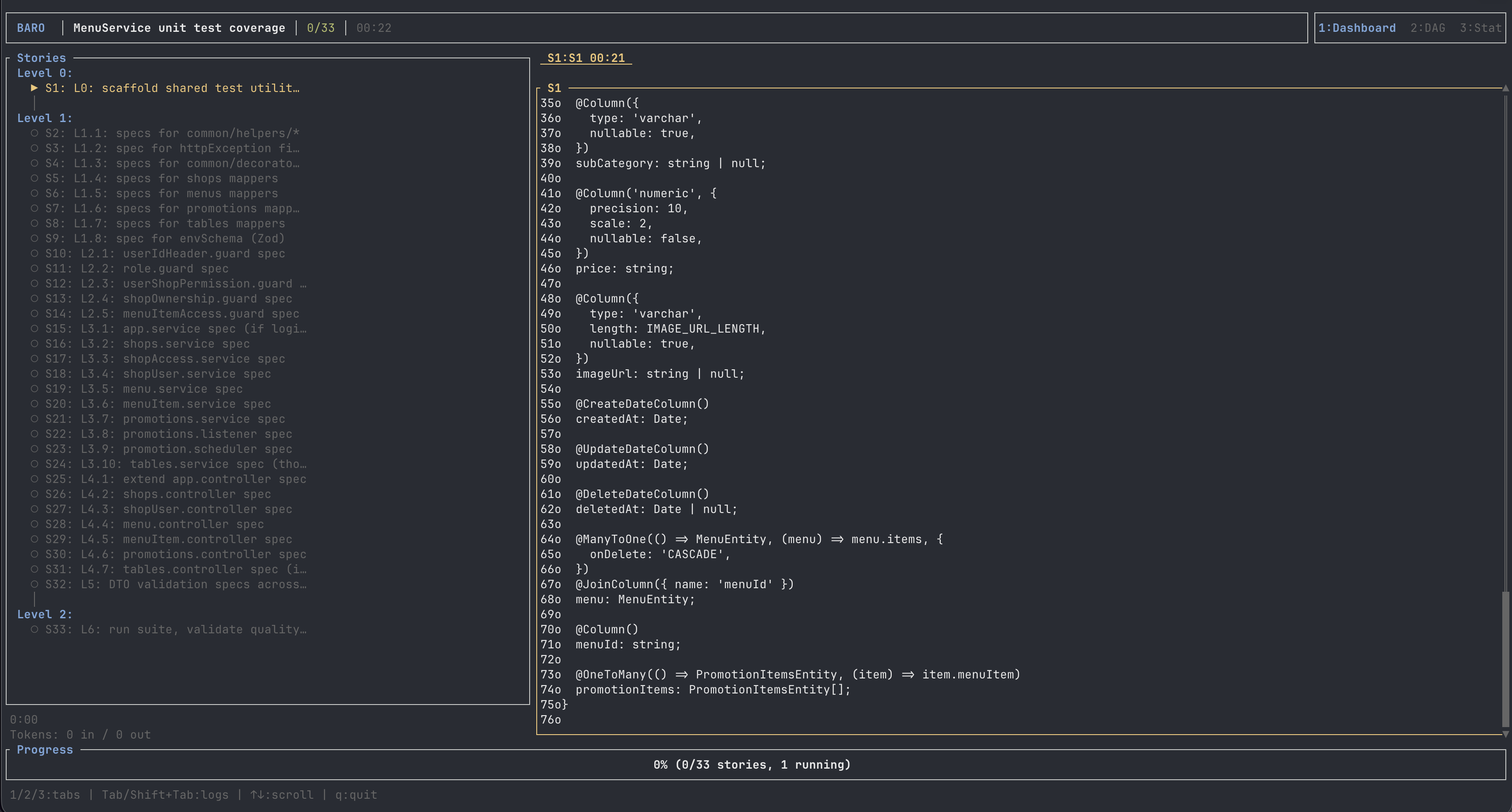
baro planning the goal into a DAG — 33 stories across parallel levels. (Click to zoom.)
I didn’t touch the keyboard for any of it. I checked back to a green PR. Is every run that clean? No — and I’ll get to where it breaks. But the shape is the point: the work fanned out, ran in parallel, reviewed itself, and converged into one reviewable artifact.
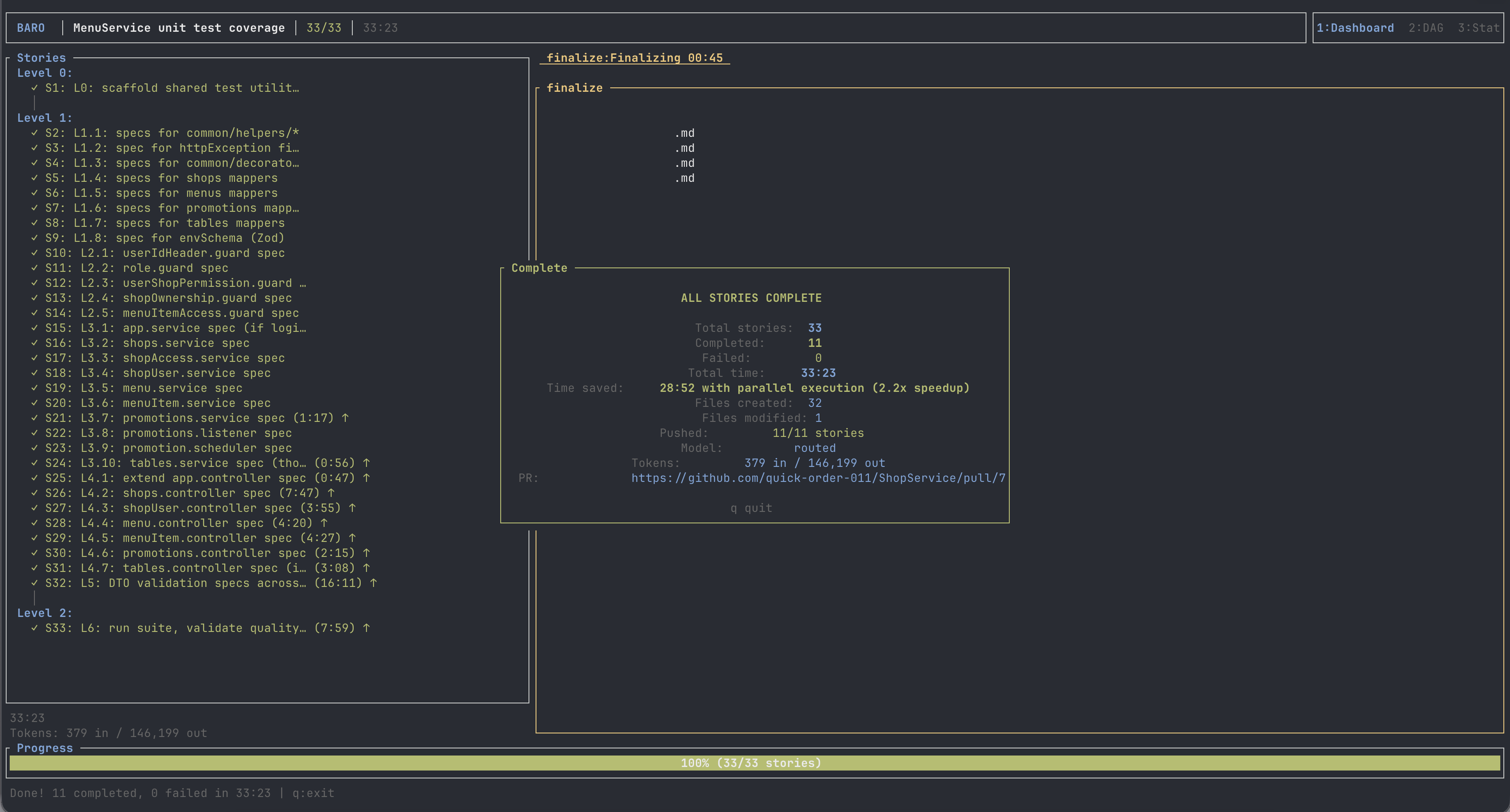
The same run, finished: 33/33 stories, ~2.2× faster in parallel, a PR opened. I reviewed it — I didn’t babysit it. (Click to zoom.)
Hand a goal to a fleet. Come back to a PR.
Start free on baro’s cloud — $5 in credits →It’s not just toy runs
The run above is reproducible, which is why I like it — but it’s a benchmark. The reason I actually trust the fleet is that I’ve shipped real work with it.
The clearest example: I used baro to scaffold an enterprise legal-tech pilot — two products on a shared core, in an afternoon.
- A RAG assistant over legal acts — cited answers, risk-tiered routing (low-risk questions answered automatically, medium ones answered-and-flagged-for-verification, high-risk ones routed to a human), expert matchmaking, and a full audit trail.
- A regulation monitor — watches external legal sources, classifies and summarizes what changed, and pushes alerts.
Both built in parallel against the same shared contracts, which is exactly where the DAG model pays off: define the core types and ports once, then let a fleet implement two products against them without drifting out of sync. The scaffold came out to roughly 6,800 lines across 110 files.
That’s the difference between “neat demo” and “I’d put this in front of a client.” The fleet isn’t just fast — it’s coordinated, because the plan is shared and the contracts are fixed before anyone writes an implementation.
Why parallel doesn’t descend into chaos
The first thing every engineer asks is: dozens of agents editing the same repo — isn’t that a merge nightmare?
It would be, if they shared a working directory. They don’t. Every story runs in its own git worktree on its own branch. Agents working in parallel are physically isolated on disk; there’s no “two agents saved the same file” race because they’re never in the same file at the same time. Integration happens deliberately, at the end, along the DAG edges — not by luck.
The other thing that keeps it sane is that the fleet is not just builders. There’s a planner that owns the decomposition, a critic that reviews each story against the goal, and a surgeon that fixes failures. Agents catch each other’s mistakes before I ever see them, which is the only reason “come back to a PR” is trustworthy instead of terrifying.
“Isn’t this just Claude Code’s /goal?”
This is the first thing people ask, so let me take it head-on — I actually tested /goal against this setup and they optimize for different shapes of the problem.
/goal gives you one Claude Code agent working a goal autonomously: it plans and executes in a single session, in one context window, on your machine, while you watch it go. It’s genuinely good — at one agent’s worth of work. But it’s still one thread: sequential steps, one context to fill up, and you in the loop.
baro is the layer above that. It plans the goal into a DAG and runs a fleet — many agents at once, each isolated in its own git worktree, reviewing each other, converging into a build-verified PR you can kick off in the cloud and walk away from. Different unit of work: /goal optimizes one autonomous agent; baro optimizes a coordinated fleet.
Here’s the part people don’t expect: baro can use Claude Code itself as the engine for each story (--llm claude shells out to Claude Code on your Max plan — or Codex, or others). So it’s less “baro vs /goal” and more “baro runs a fleet of the agent /goal gives you exactly one of.” If you like /goal, baro is what happens when you want twelve of it, coordinated, with a PR at the end.
Then I took it off my laptop
For a while the fleet ran locally. And running a dozen agents on your own machine has… costs. Your fans spin up. Your CPU is pinned. You can’t close the lid or the run dies. You’re tied to the desk you started it from. The “stop babysitting” win was real, but I’d traded babysitting for being a server.
So I gave the agents a cloud.
Now I fire a goal and it runs in an isolated sandbox — not my machine. I can start a run from my phone, close my laptop, go get coffee, and get an email when the PR is open. Each run is sandboxed and disposable. There’s nothing to install and nothing pinning my hardware.
That’s the part that actually changed my habits. “Fire and forget” only works if forgetting doesn’t mean babysitting a process on your own laptop. The cloud is what made the delegation real. (If you’d rather keep it on your own hardware — over your Claude Max, ChatGPT Pro, or OpenCode subscription, with your code never leaving your machine — that still works. The point isn’t where it runs. It’s that you hand off a goal instead of supervising an agent.)
Fire a run from anywhere. Get an email when the PR is open.
Try baro’s cloud — $5 free, nothing to install →When it shines, and when it doesn’t
I’d rather you trust this post than be impressed by it, so:
It shines when the work is well-specified and verifiable — features with clear acceptance criteria, test-backed changes, “build X that does Y,” large mechanical changes, anything you could write a ticket for. The DAG + parallelism + build-gate really earn their keep here.
It struggles when the goal is vague or exploratory — “make the app feel faster,” “figure out why this is flaky.” Fan-out doesn’t help if the problem is fundamentally one of judgment in a single thread. For that, I still open a chat and babysit. The fleet is for building, not for deciding what to build.
And parallel isn’t free — more agents means more tokens. But a full feature still lands in the low single-digit dollars on the cloud, and pennies for small tasks. For me, an afternoon of my time vs a couple of dollars and a coffee break isn’t a close call.
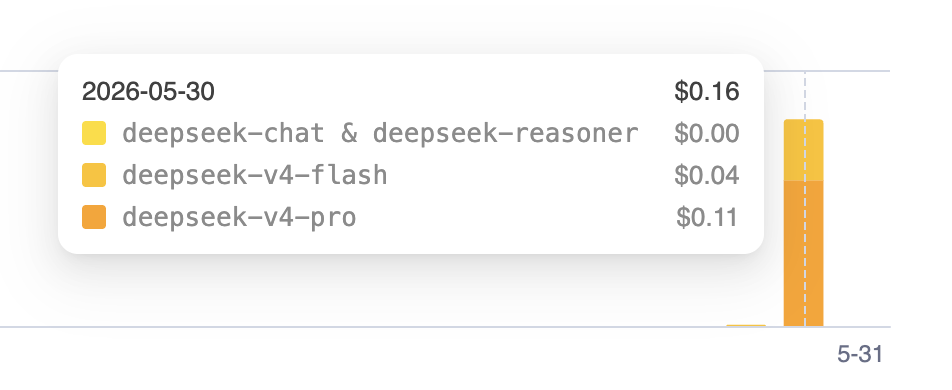
The underlying economics: a full day of agent runs on a DeepSeek-backed setup — $0.16. That’s why the tail is pennies. (I dug into this in The Economics of Parallel Coding Agents.)
Try it
If “I give a goal, I get a PR” sounds better than “I supervise an agent,” that’s the whole pitch.
- baro’s cloud — nothing to install, each run sandboxed, pay as you go. New accounts get $5 in free credits, which is a few real runs to see if it clicks.
- Your own machine — bring your Claude / Codex / OpenCode subscription and run the same fleet locally.
I’m genuinely curious where it breaks for your codebase — that’s the feedback I want most. Tell me what you throw at it.
P.S. — if you scrolled all the way down here from daily.dev: use code DAILYDEV for 50% off your first cloud credits at baro.rs. Thanks for reading. 🙏

Different is better than better.
